|
Darknet/YOLO v5.0-41-g593bddc
Object Detection Framework
|

|
|
Darknet/YOLO v5.0-41-g593bddc
Object Detection Framework
|
|
Functions | |
| __global__ void | activate_array_gelu_kernel (float *x, int n) |
| __global__ void | activate_array_hard_mish_kernel (float *x, int n, float *activation_input, float *output_gpu) |
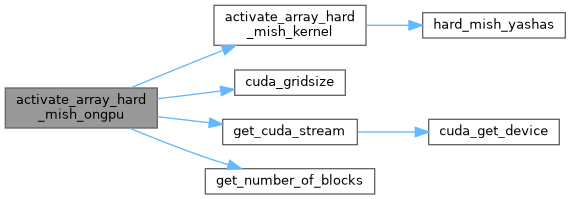
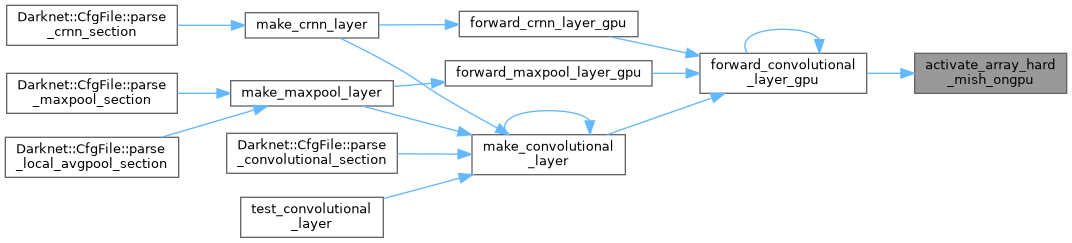
| void | activate_array_hard_mish_ongpu (float *x, int n, float *activation_input_gpu, float *output_gpu) |
| __global__ void | activate_array_hardtan_kernel (float *x, int n) |
| __global__ void | activate_array_kernel (float *x, int n, ACTIVATION a) |
| __global__ void | activate_array_leaky_kernel (float *x, int n) |
| __global__ void | activate_array_logistic_kernel (float *x, int n) |
| __global__ void | activate_array_mish_kernel (float *x, int n, float *activation_input, float *output_gpu) |
| void | activate_array_mish_ongpu (float *x, int n, float *activation_input_gpu, float *output_gpu) |
| __global__ void | activate_array_normalize_channels_kernel (float *x, int size, int batch, int channels, int wh_step, float *output_gpu) |
| void | activate_array_normalize_channels_ongpu (float *x, int n, int batch, int channels, int wh_step, float *output_gpu) |
| __global__ void | activate_array_normalize_channels_softmax_kernel (float *x, int size, int batch, int channels, int wh_step, float *output_gpu, int use_max_val) |
| void | activate_array_normalize_channels_softmax_ongpu (float *x, int n, int batch, int channels, int wh_step, float *output_gpu, int use_max_val) |
| void | activate_array_ongpu (float *x, int n, ACTIVATION a) |
| __global__ void | activate_array_relu6_kernel (float *x, int n) |
| __global__ void | activate_array_relu_kernel (float *x, int n) |
| __global__ void | activate_array_selu_kernel (float *x, int n) |
| __global__ void | activate_array_swish_kernel (float *x, int n, float *output_sigmoid_gpu, float *output_gpu) |
| void | activate_array_swish_ongpu (float *x, int n, float *output_sigmoid_gpu, float *output_gpu) |
| __global__ void | activate_array_tanh_kernel (float *x, int n) |
| __device__ float | activate_kernel (float x, ACTIVATION a) |
| void | binary_activate_array_gpu (float *x, int n, int size, BINARY_ACTIVATION a, float *y) |
| __global__ void | binary_activate_array_kernel (float *x, int n, int s, BINARY_ACTIVATION a, float *y) |
| void | binary_gradient_array_gpu (float *x, float *dx, int n, int size, BINARY_ACTIVATION a, float *y) |
| __global__ void | binary_gradient_array_kernel (float *x, float *dy, int n, int s, BINARY_ACTIVATION a, float *dx) |
| __device__ float | elu_activate_kernel (float x) |
| __device__ float | elu_gradient_kernel (float x) |
| __device__ float | gelu_activate_kernel (float x) |
| __device__ float | gelu_gradient_kernel (float x) |
| __global__ void | gradient_array_gelu_kernel (float *x, int n, float *delta) |
| __global__ void | gradient_array_hard_mish_kernel (int n, float *activation_input_gpu, float *delta) |
| void | gradient_array_hard_mish_ongpu (int n, float *activation_input_gpu, float *delta) |
| __global__ void | gradient_array_hardtan_kernel (float *x, int n, float *delta) |
| __global__ void | gradient_array_kernel (float *x, int n, ACTIVATION a, float *delta) |
| __global__ void | gradient_array_leaky_kernel (float *x, int n, float *delta) |
| __global__ void | gradient_array_logistic_kernel (float *x, int n, float *delta) |
| __global__ void | gradient_array_mish_kernel (int n, float *activation_input_gpu, float *delta) |
| void | gradient_array_mish_ongpu (int n, float *activation_input_gpu, float *delta) |
| __global__ void | gradient_array_normalize_channels_kernel (float *x, int size, int batch, int channels, int wh_step, float *delta_gpu) |
| void | gradient_array_normalize_channels_ongpu (float *output_gpu, int n, int batch, int channels, int wh_step, float *delta_gpu) |
| __global__ void | gradient_array_normalize_channels_softmax_kernel (float *x, int size, int batch, int channels, int wh_step, float *delta_gpu) |
| void | gradient_array_normalize_channels_softmax_ongpu (float *output_gpu, int n, int batch, int channels, int wh_step, float *delta_gpu) |
| void | gradient_array_ongpu (float *x, int n, ACTIVATION a, float *delta) |
| __global__ void | gradient_array_relu6_kernel (float *x, int n, float *delta) |
| __global__ void | gradient_array_relu_kernel (float *x, int n, float *delta) |
| __global__ void | gradient_array_revleaky_kernel (float *x, int n, float *delta) |
| __global__ void | gradient_array_selu_kernel (float *x, int n, float *delta) |
| __global__ void | gradient_array_swish_kernel (float *x, int n, float *sigmoid_gpu, float *delta) |
| void | gradient_array_swish_ongpu (float *x, int n, float *sigmoid_gpu, float *delta) |
| __global__ void | gradient_array_tanh_kernel (float *x, int n, float *delta) |
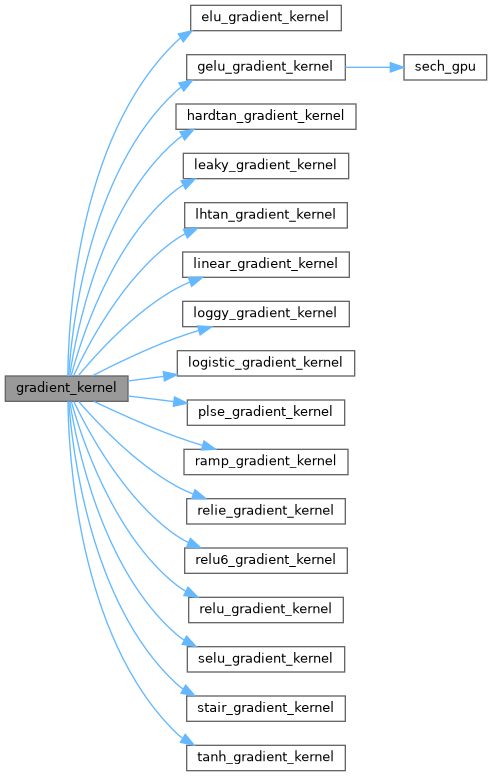
| __device__ float | gradient_kernel (float x, ACTIVATION a) |
| __device__ float | hard_mish_yashas (float x) |
| __device__ float | hard_mish_yashas_grad (float x) |
| __device__ float | hardtan_activate_kernel (float x) |
| __device__ float | hardtan_gradient_kernel (float x) |
| __device__ float | leaky_activate_kernel (float x) |
| __device__ float | leaky_gradient_kernel (float x) |
| __device__ float | lhtan_activate_kernel (float x) |
| __device__ float | lhtan_gradient_kernel (float x) |
| __device__ float | linear_activate_kernel (float x) |
| __device__ float | linear_gradient_kernel (float x) |
| __device__ float | loggy_activate_kernel (float x) |
| __device__ float | loggy_gradient_kernel (float x) |
| __device__ float | logistic_activate_kernel (float x) |
| __device__ float | logistic_gradient_kernel (float x) |
| __device__ float | mish_njuffa (float x) |
| __device__ float | mish_yashas (float x) |
| __device__ float | mish_yashas2 (float x) |
| __device__ float | plse_activate_kernel (float x) |
| __device__ float | plse_gradient_kernel (float x) |
| __device__ float | ramp_activate_kernel (float x) |
| __device__ float | ramp_gradient_kernel (float x) |
| __device__ float | relie_activate_kernel (float x) |
| __device__ float | relie_gradient_kernel (float x) |
| __device__ float | relu6_activate_kernel (float x) |
| __device__ float | relu6_gradient_kernel (float x) |
| __device__ float | relu_activate_kernel (float x) |
| __device__ float | relu_gradient_kernel (float x) |
| __device__ float | sech_gpu (float x) |
| __device__ float | selu_activate_kernel (float x) |
| __device__ float | selu_gradient_kernel (float x) |
| __device__ float | softplus_kernel (float x, float threshold=20) |
| __device__ float | stair_activate_kernel (float x) |
| __device__ float | stair_gradient_kernel (float x) |
| __device__ float | tanh_activate_kernel (float x) |
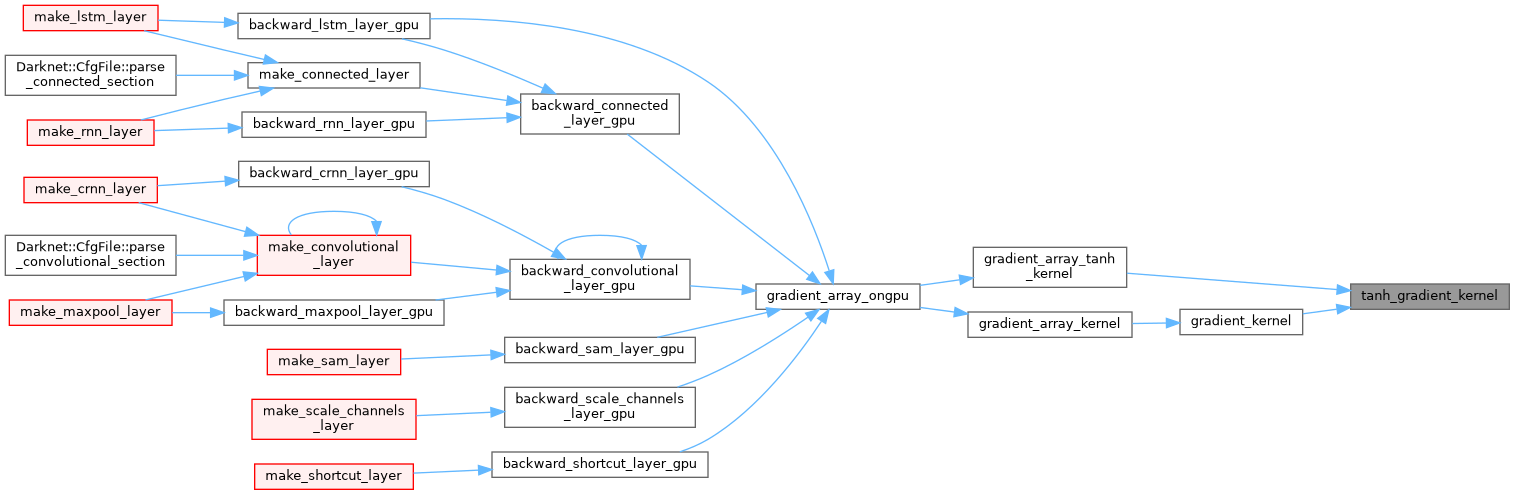
| __device__ float | tanh_gradient_kernel (float x) |
| __global__ void activate_array_gelu_kernel | ( | float * | x, |
| int | n | ||
| ) |

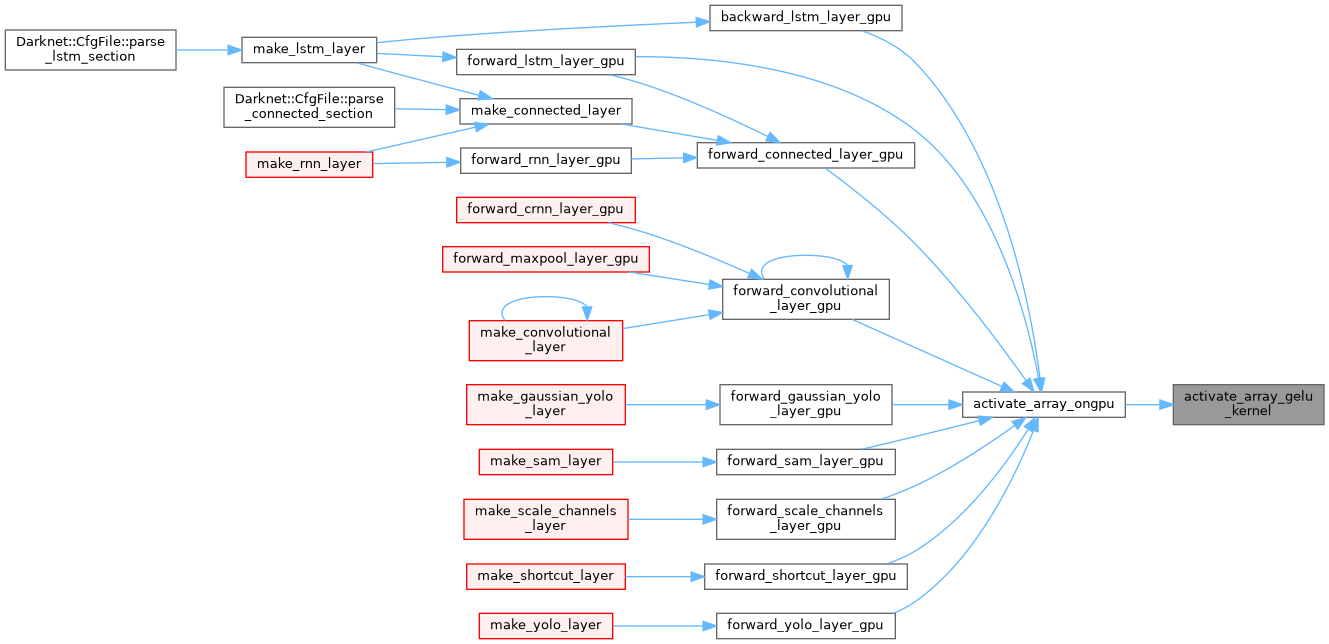
| __global__ void activate_array_hard_mish_kernel | ( | float * | x, |
| int | n, | ||
| float * | activation_input, | ||
| float * | output_gpu | ||
| ) |


| void activate_array_hard_mish_ongpu | ( | float * | x, |
| int | n, | ||
| float * | activation_input_gpu, | ||
| float * | output_gpu | ||
| ) |
| __global__ void activate_array_hardtan_kernel | ( | float * | x, |
| int | n | ||
| ) |

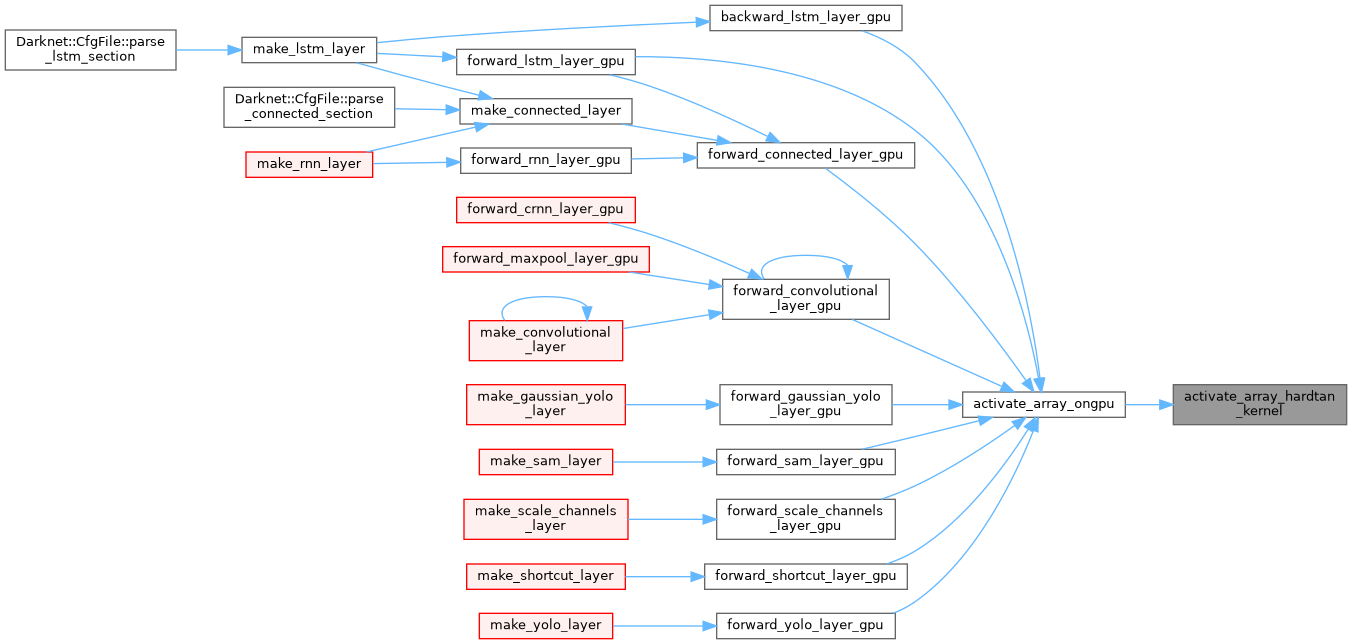
| __global__ void activate_array_kernel | ( | float * | x, |
| int | n, | ||
| ACTIVATION | a | ||
| ) |
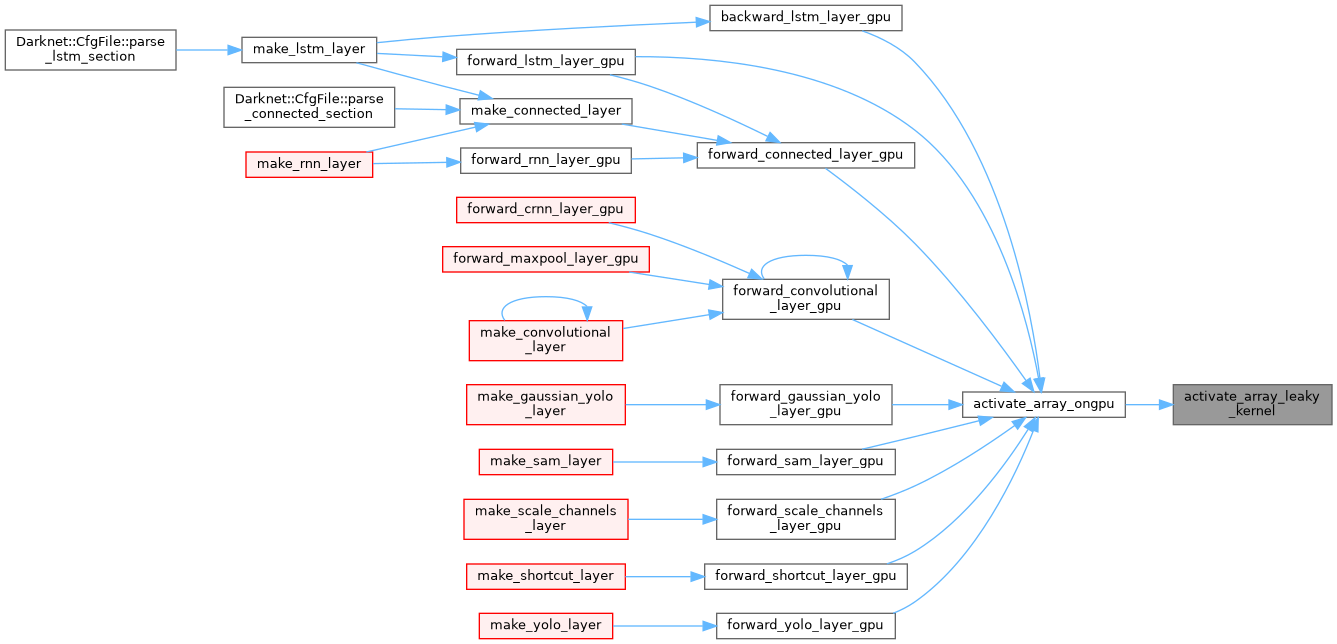
| __global__ void activate_array_leaky_kernel | ( | float * | x, |
| int | n | ||
| ) |

| __global__ void activate_array_logistic_kernel | ( | float * | x, |
| int | n | ||
| ) |

| __global__ void activate_array_mish_kernel | ( | float * | x, |
| int | n, | ||
| float * | activation_input, | ||
| float * | output_gpu | ||
| ) |

| void activate_array_mish_ongpu | ( | float * | x, |
| int | n, | ||
| float * | activation_input_gpu, | ||
| float * | output_gpu | ||
| ) |
| __global__ void activate_array_normalize_channels_kernel | ( | float * | x, |
| int | size, | ||
| int | batch, | ||
| int | channels, | ||
| int | wh_step, | ||
| float * | output_gpu | ||
| ) |

| void activate_array_normalize_channels_ongpu | ( | float * | x, |
| int | n, | ||
| int | batch, | ||
| int | channels, | ||
| int | wh_step, | ||
| float * | output_gpu | ||
| ) |

| __global__ void activate_array_normalize_channels_softmax_kernel | ( | float * | x, |
| int | size, | ||
| int | batch, | ||
| int | channels, | ||
| int | wh_step, | ||
| float * | output_gpu, | ||
| int | use_max_val | ||
| ) |

| void activate_array_normalize_channels_softmax_ongpu | ( | float * | x, |
| int | n, | ||
| int | batch, | ||
| int | channels, | ||
| int | wh_step, | ||
| float * | output_gpu, | ||
| int | use_max_val | ||
| ) |

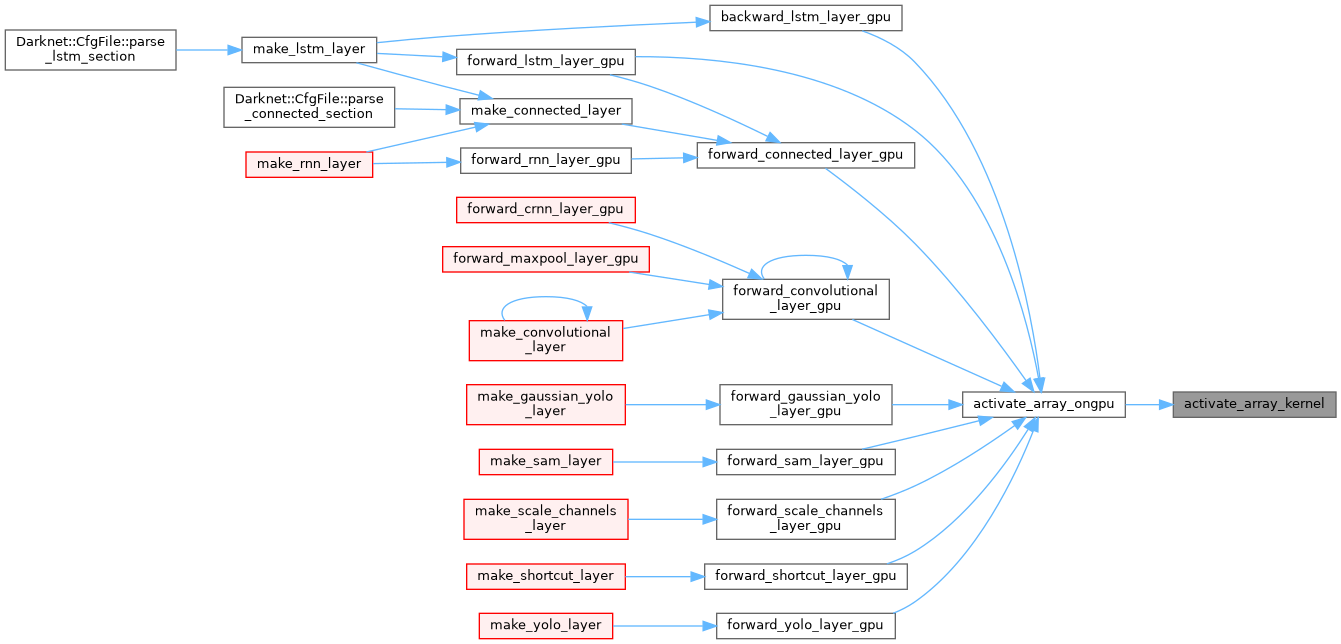
| void activate_array_ongpu | ( | float * | x, |
| int | n, | ||
| ACTIVATION | a | ||
| ) |
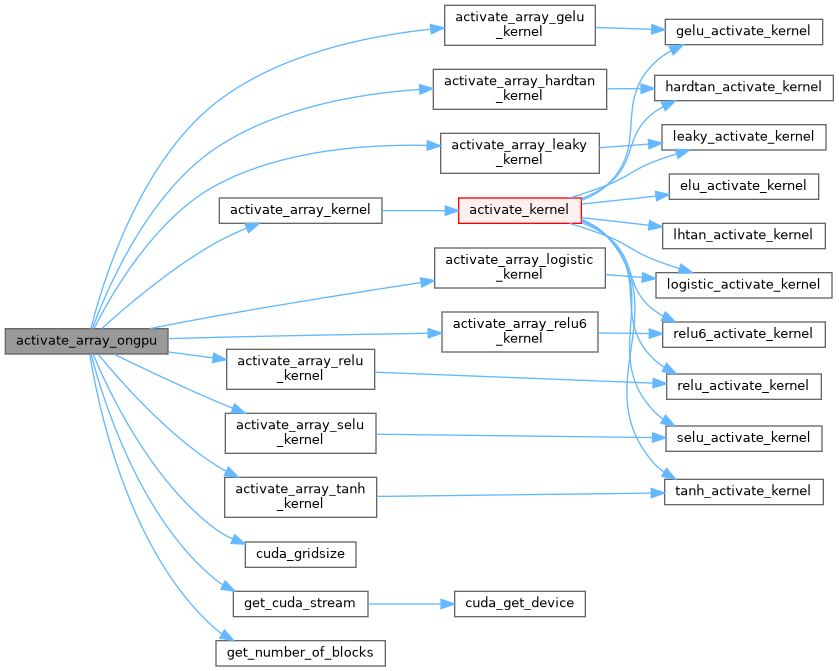
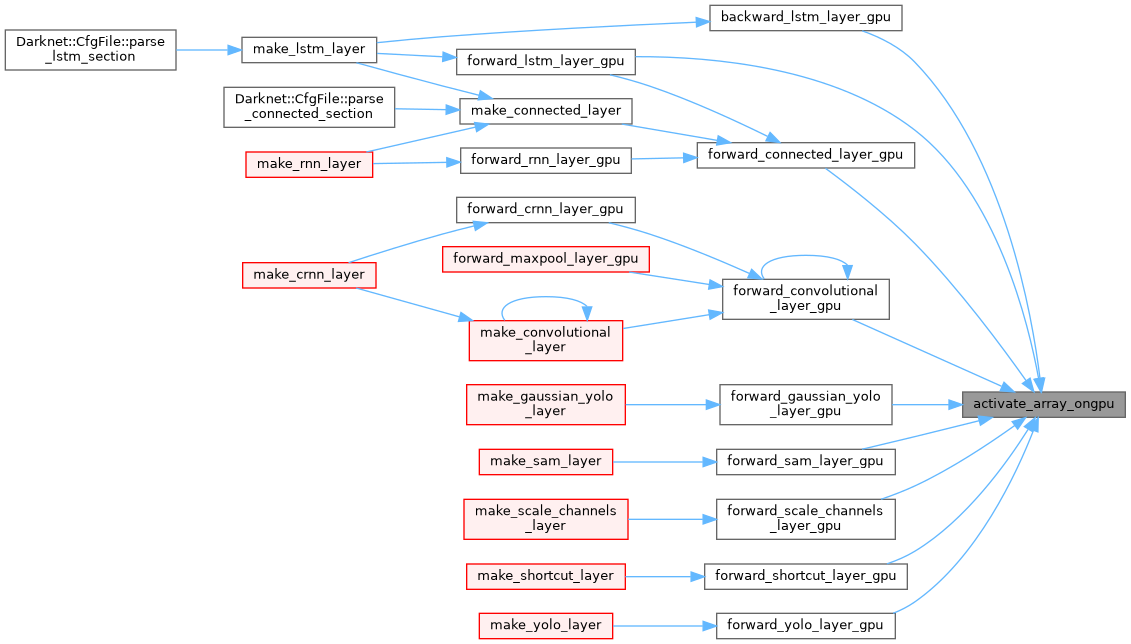
| __global__ void activate_array_relu6_kernel | ( | float * | x, |
| int | n | ||
| ) |

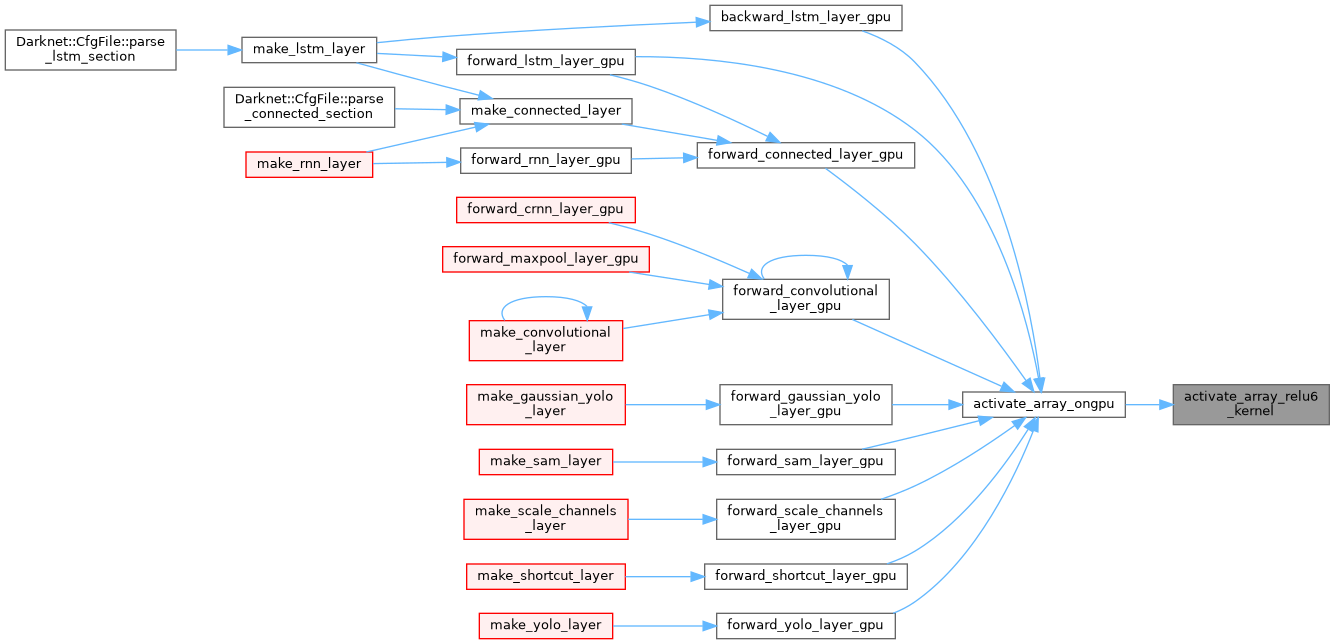
| __global__ void activate_array_relu_kernel | ( | float * | x, |
| int | n | ||
| ) |

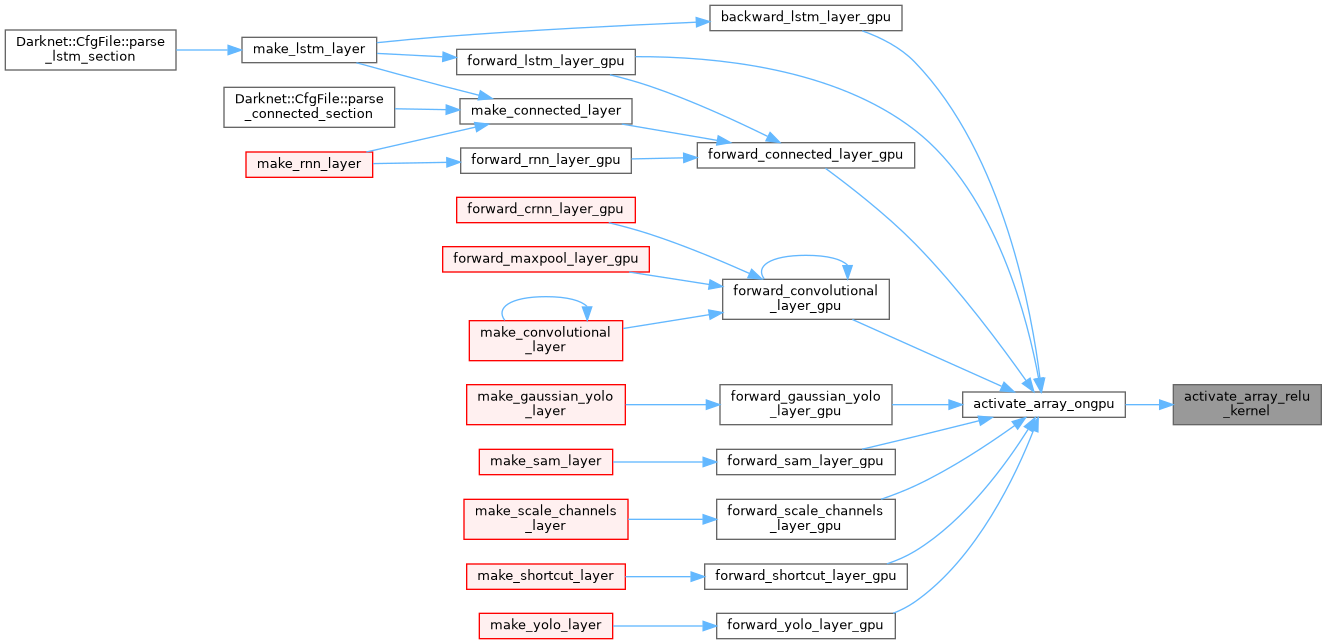
| __global__ void activate_array_selu_kernel | ( | float * | x, |
| int | n | ||
| ) |

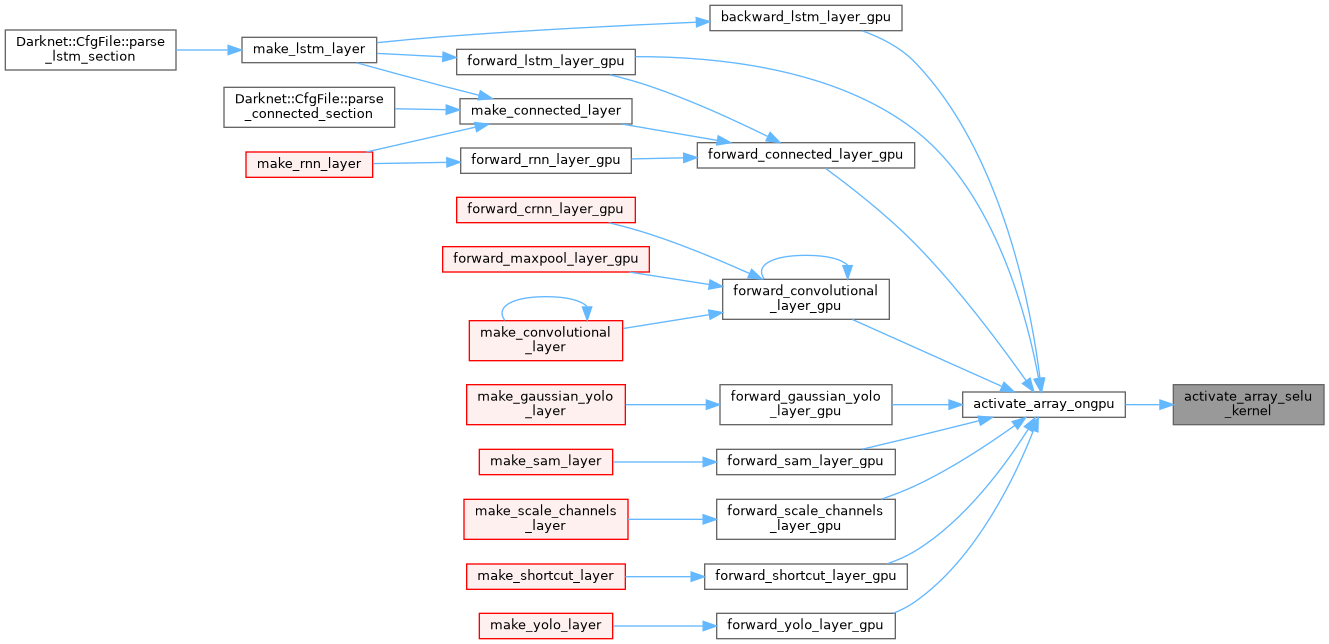
| __global__ void activate_array_swish_kernel | ( | float * | x, |
| int | n, | ||
| float * | output_sigmoid_gpu, | ||
| float * | output_gpu | ||
| ) |

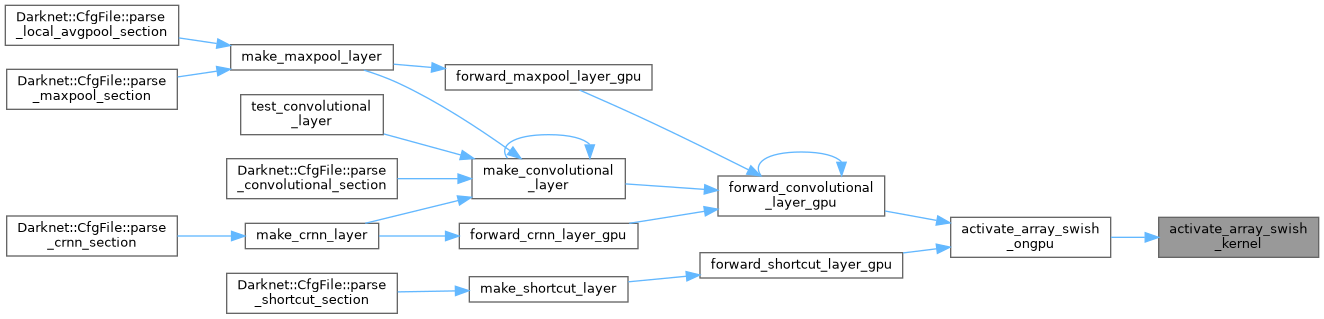
| void activate_array_swish_ongpu | ( | float * | x, |
| int | n, | ||
| float * | output_sigmoid_gpu, | ||
| float * | output_gpu | ||
| ) |
| __global__ void activate_array_tanh_kernel | ( | float * | x, |
| int | n | ||
| ) |

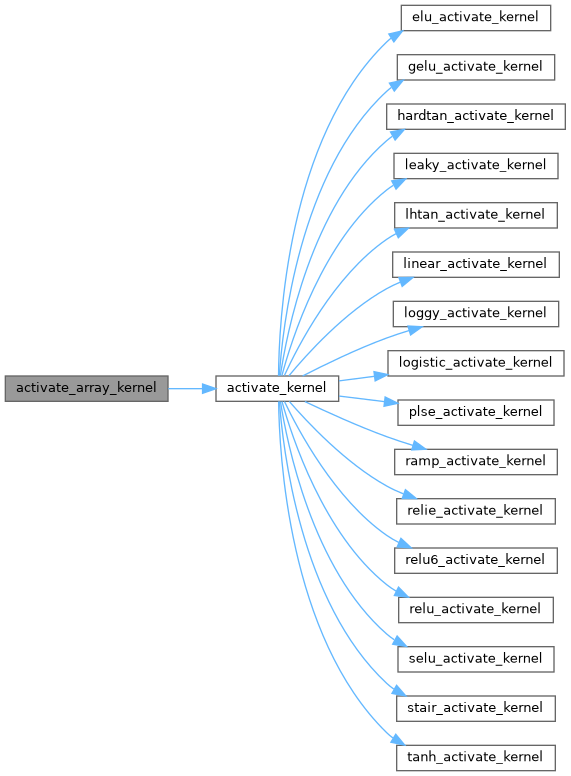
| __device__ float activate_kernel | ( | float | x, |
| ACTIVATION | a | ||
| ) |
| void binary_activate_array_gpu | ( | float * | x, |
| int | n, | ||
| int | size, | ||
| BINARY_ACTIVATION | a, | ||
| float * | y | ||
| ) |
| __global__ void binary_activate_array_kernel | ( | float * | x, |
| int | n, | ||
| int | s, | ||
| BINARY_ACTIVATION | a, | ||
| float * | y | ||
| ) |

| void binary_gradient_array_gpu | ( | float * | x, |
| float * | dx, | ||
| int | n, | ||
| int | size, | ||
| BINARY_ACTIVATION | a, | ||
| float * | y | ||
| ) |
| __global__ void binary_gradient_array_kernel | ( | float * | x, |
| float * | dy, | ||
| int | n, | ||
| int | s, | ||
| BINARY_ACTIVATION | a, | ||
| float * | dx | ||
| ) |

| __device__ float elu_activate_kernel | ( | float | x | ) |
| __device__ float elu_gradient_kernel | ( | float | x | ) |
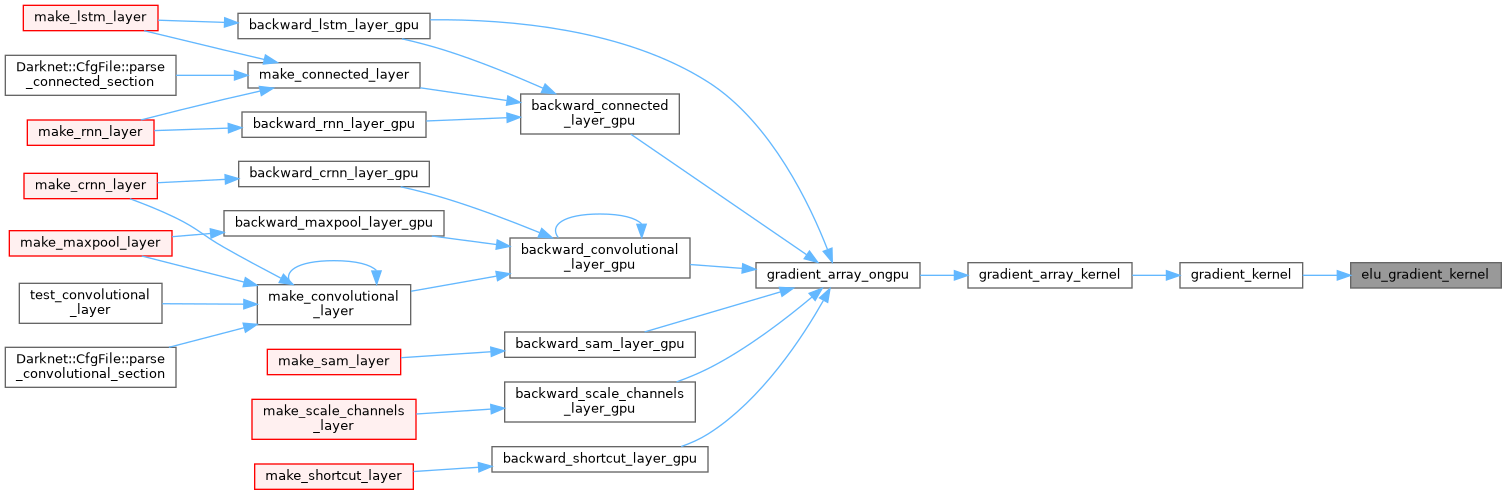
| __device__ float gelu_activate_kernel | ( | float | x | ) |
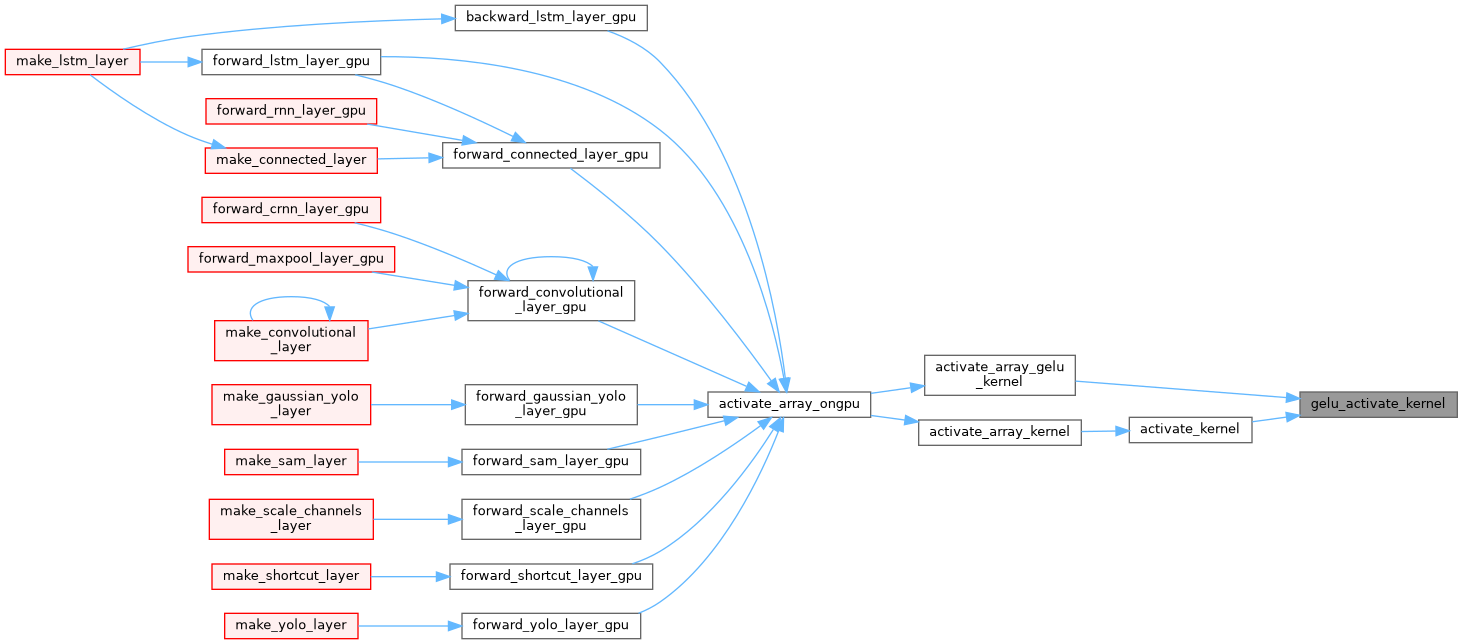
| __device__ float gelu_gradient_kernel | ( | float | x | ) |

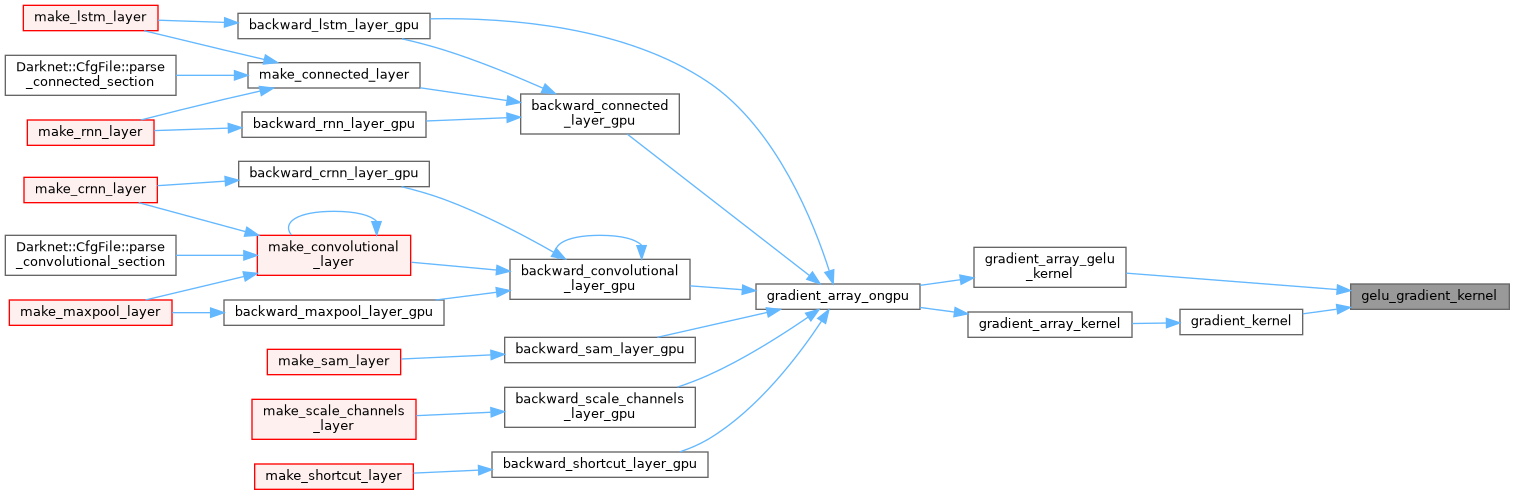
| __global__ void gradient_array_gelu_kernel | ( | float * | x, |
| int | n, | ||
| float * | delta | ||
| ) |

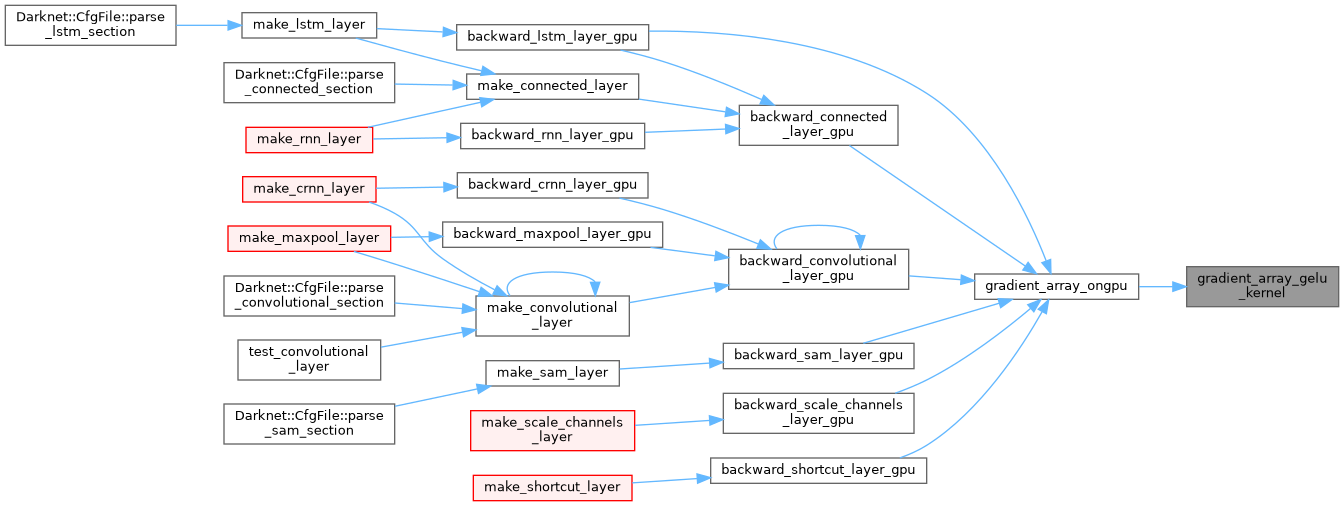
| __global__ void gradient_array_hard_mish_kernel | ( | int | n, |
| float * | activation_input_gpu, | ||
| float * | delta | ||
| ) |


| void gradient_array_hard_mish_ongpu | ( | int | n, |
| float * | activation_input_gpu, | ||
| float * | delta | ||
| ) |
| __global__ void gradient_array_hardtan_kernel | ( | float * | x, |
| int | n, | ||
| float * | delta | ||
| ) |

| __global__ void gradient_array_kernel | ( | float * | x, |
| int | n, | ||
| ACTIVATION | a, | ||
| float * | delta | ||
| ) |
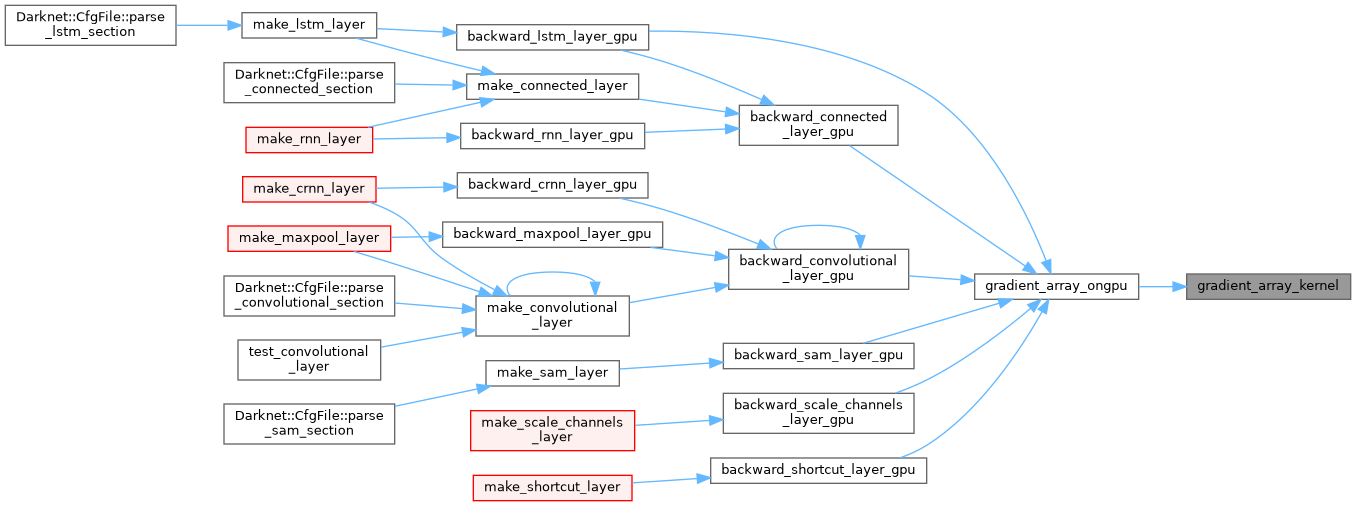
| __global__ void gradient_array_leaky_kernel | ( | float * | x, |
| int | n, | ||
| float * | delta | ||
| ) |

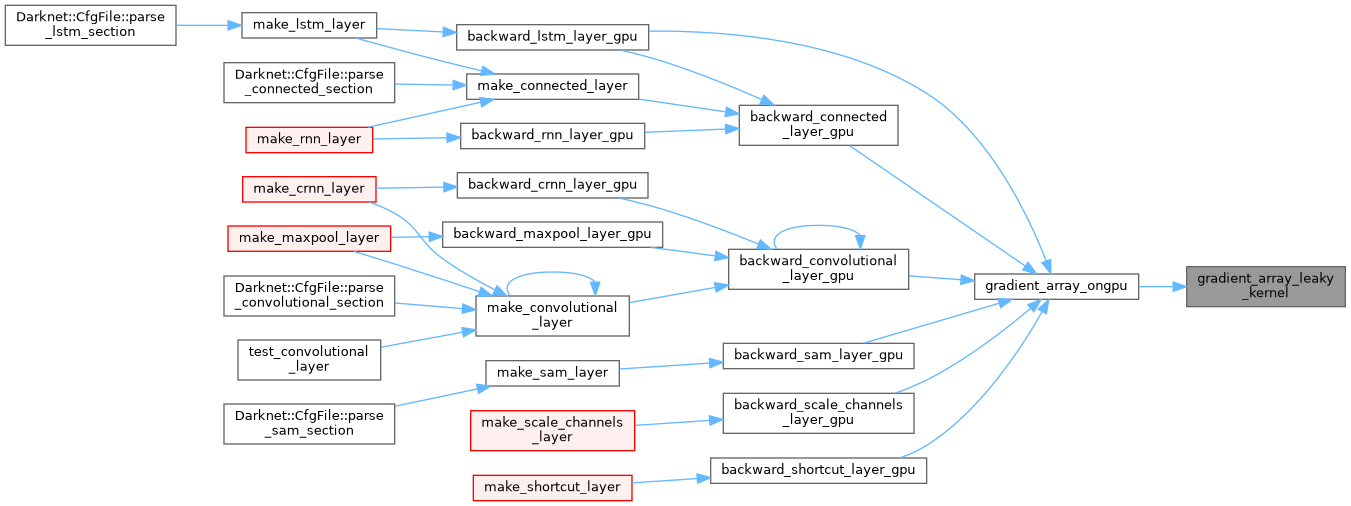
| __global__ void gradient_array_logistic_kernel | ( | float * | x, |
| int | n, | ||
| float * | delta | ||
| ) |

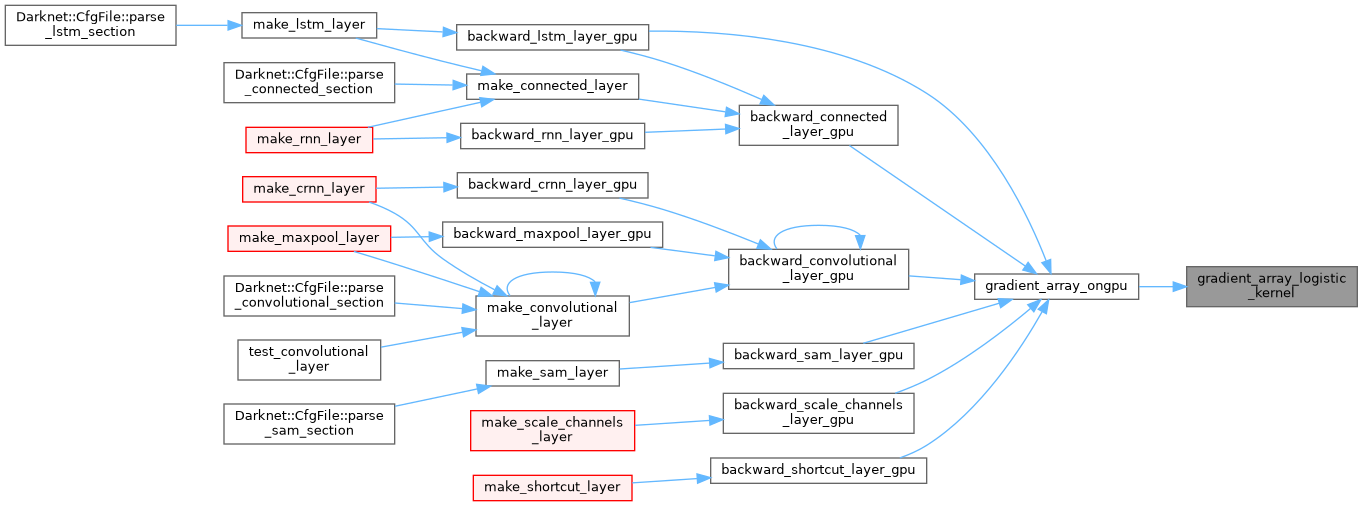
| __global__ void gradient_array_mish_kernel | ( | int | n, |
| float * | activation_input_gpu, | ||
| float * | delta | ||
| ) |

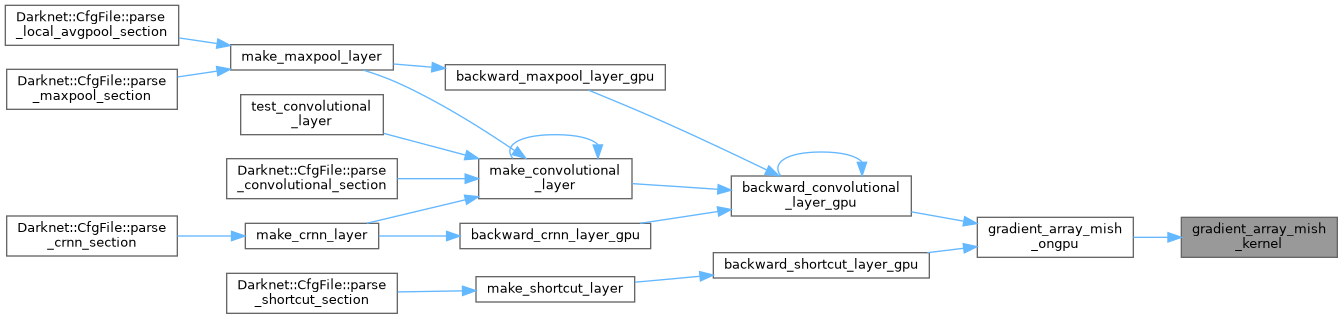
| void gradient_array_mish_ongpu | ( | int | n, |
| float * | activation_input_gpu, | ||
| float * | delta | ||
| ) |
| __global__ void gradient_array_normalize_channels_kernel | ( | float * | x, |
| int | size, | ||
| int | batch, | ||
| int | channels, | ||
| int | wh_step, | ||
| float * | delta_gpu | ||
| ) |

| void gradient_array_normalize_channels_ongpu | ( | float * | output_gpu, |
| int | n, | ||
| int | batch, | ||
| int | channels, | ||
| int | wh_step, | ||
| float * | delta_gpu | ||
| ) |

| __global__ void gradient_array_normalize_channels_softmax_kernel | ( | float * | x, |
| int | size, | ||
| int | batch, | ||
| int | channels, | ||
| int | wh_step, | ||
| float * | delta_gpu | ||
| ) |

| void gradient_array_normalize_channels_softmax_ongpu | ( | float * | output_gpu, |
| int | n, | ||
| int | batch, | ||
| int | channels, | ||
| int | wh_step, | ||
| float * | delta_gpu | ||
| ) |

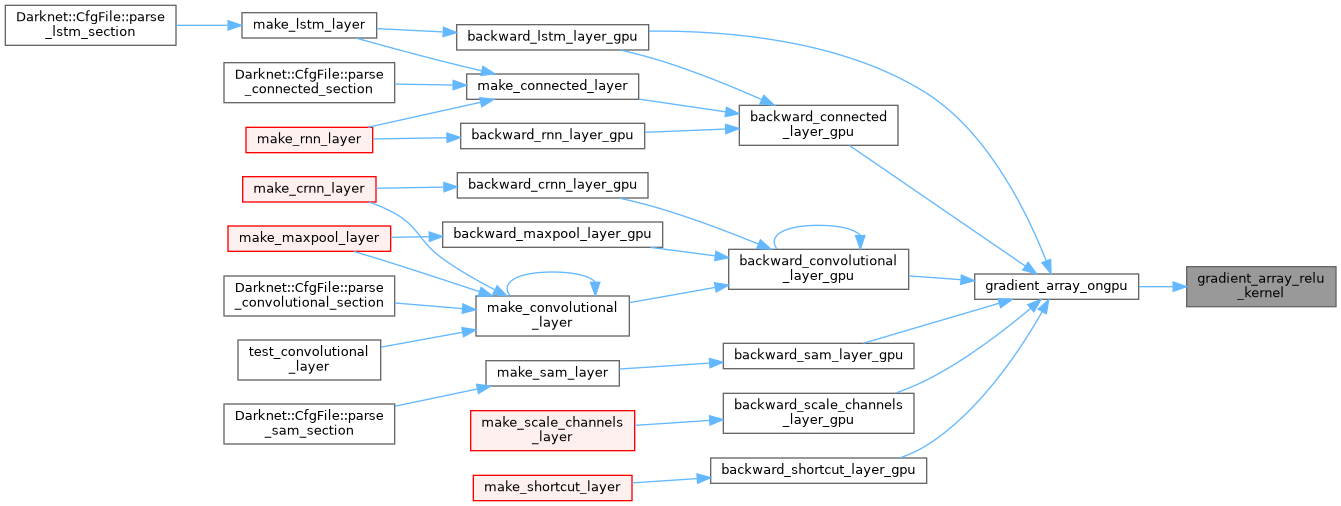
| void gradient_array_ongpu | ( | float * | x, |
| int | n, | ||
| ACTIVATION | a, | ||
| float * | delta | ||
| ) |
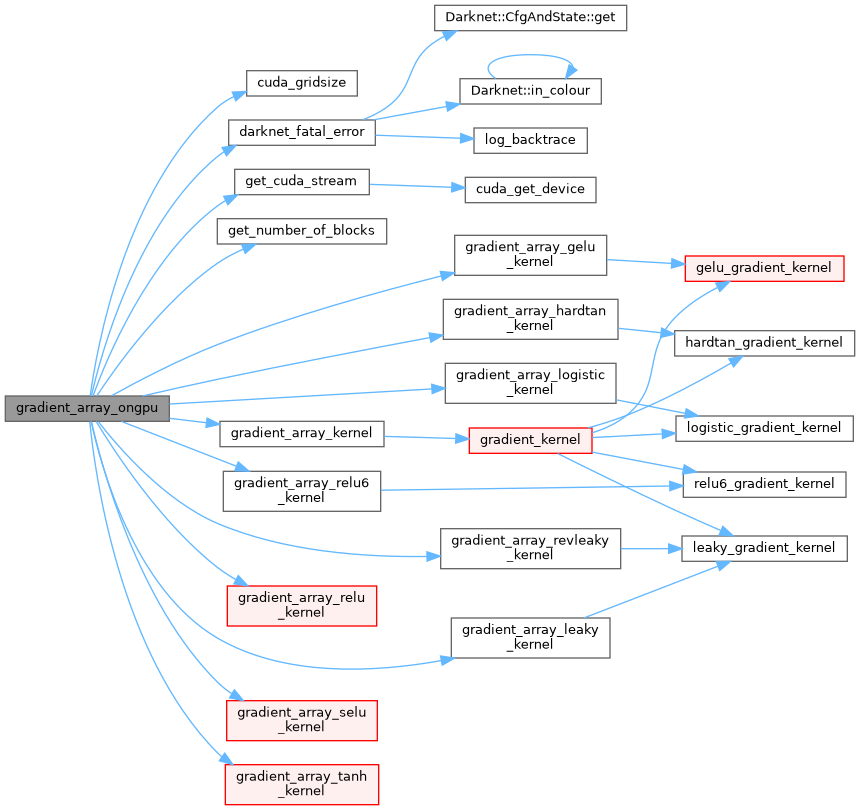
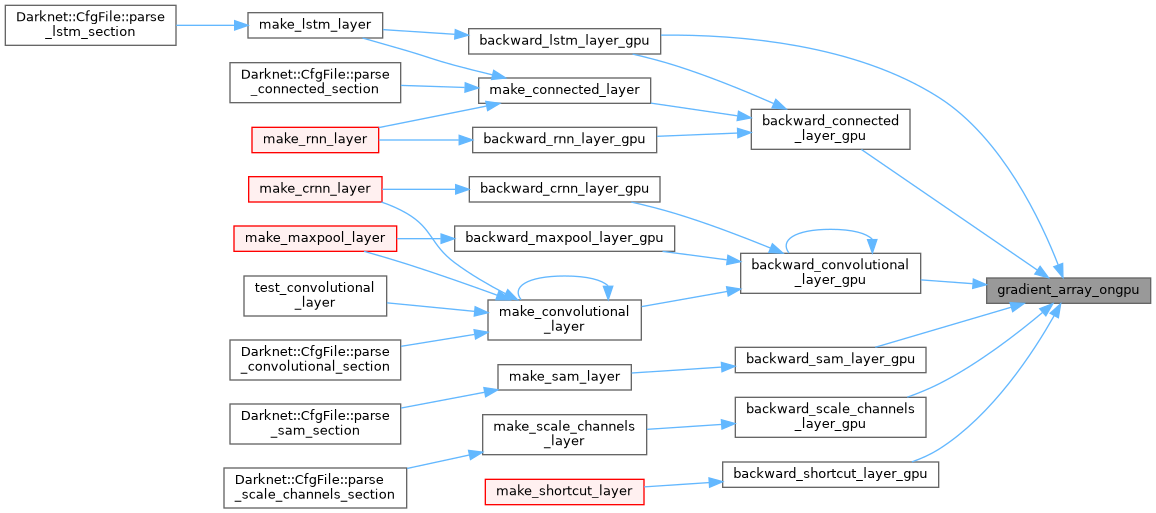
| __global__ void gradient_array_relu6_kernel | ( | float * | x, |
| int | n, | ||
| float * | delta | ||
| ) |

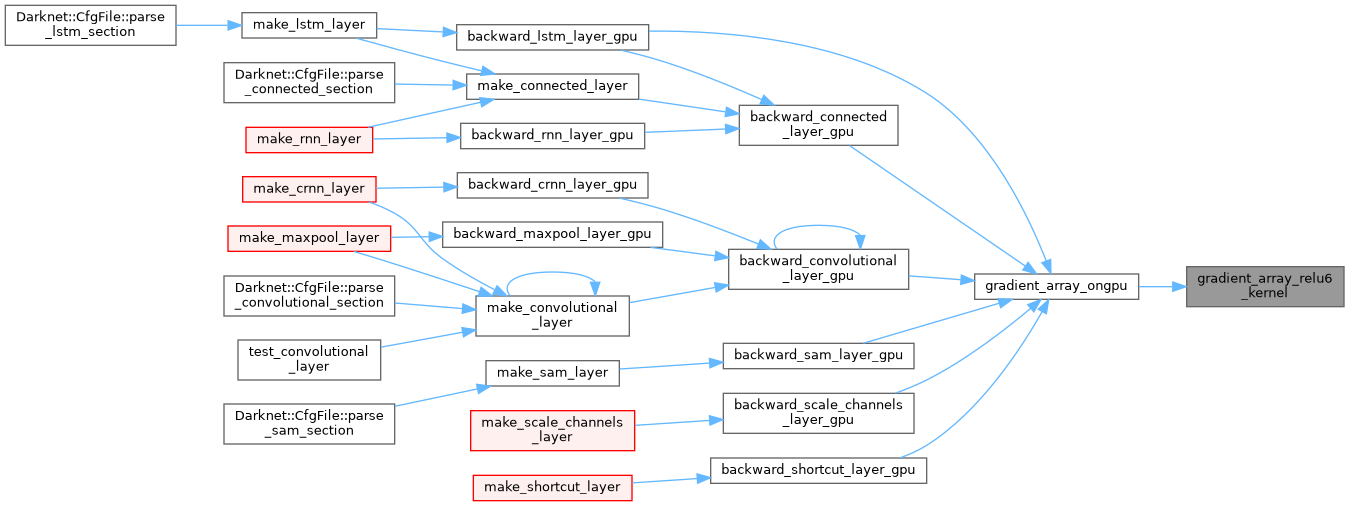
| __global__ void gradient_array_relu_kernel | ( | float * | x, |
| int | n, | ||
| float * | delta | ||
| ) |

| __global__ void gradient_array_revleaky_kernel | ( | float * | x, |
| int | n, | ||
| float * | delta | ||
| ) |

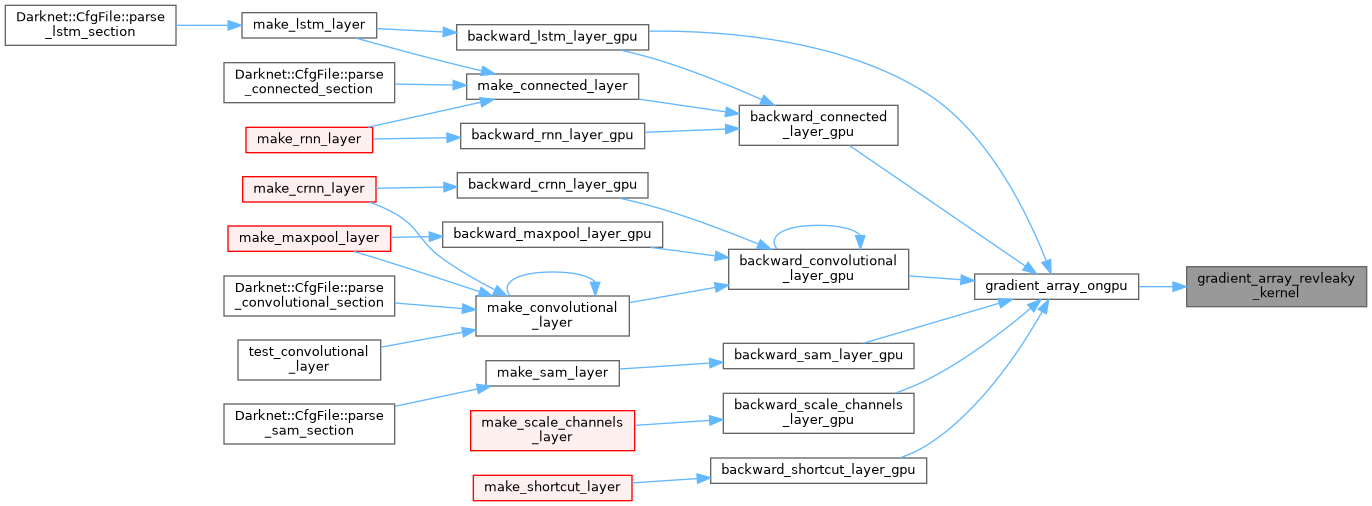
| __global__ void gradient_array_selu_kernel | ( | float * | x, |
| int | n, | ||
| float * | delta | ||
| ) |

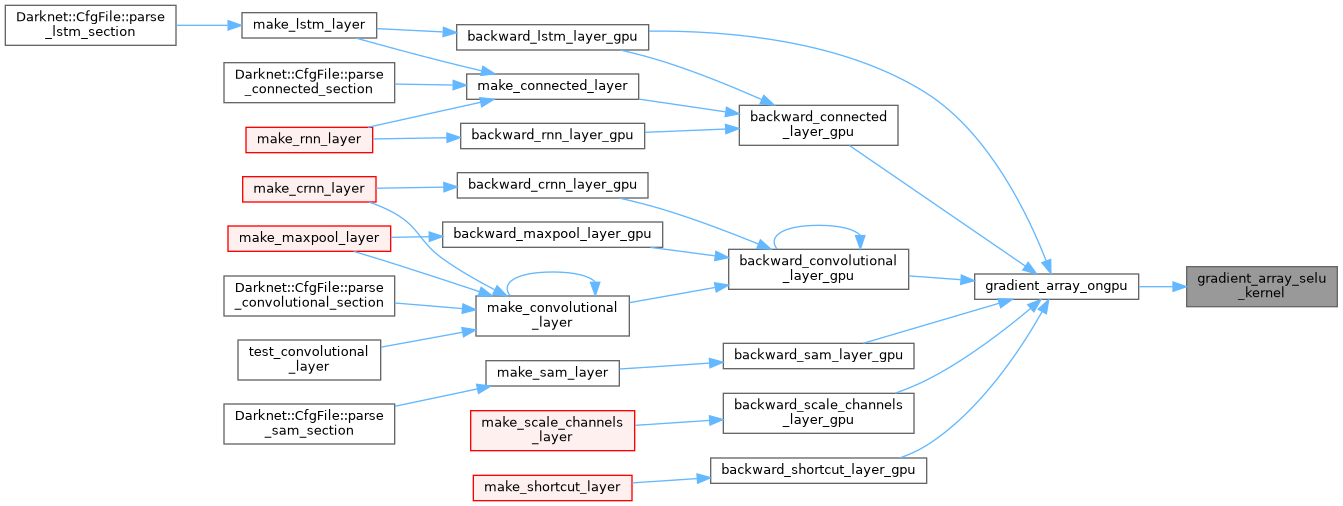
| __global__ void gradient_array_swish_kernel | ( | float * | x, |
| int | n, | ||
| float * | sigmoid_gpu, | ||
| float * | delta | ||
| ) |
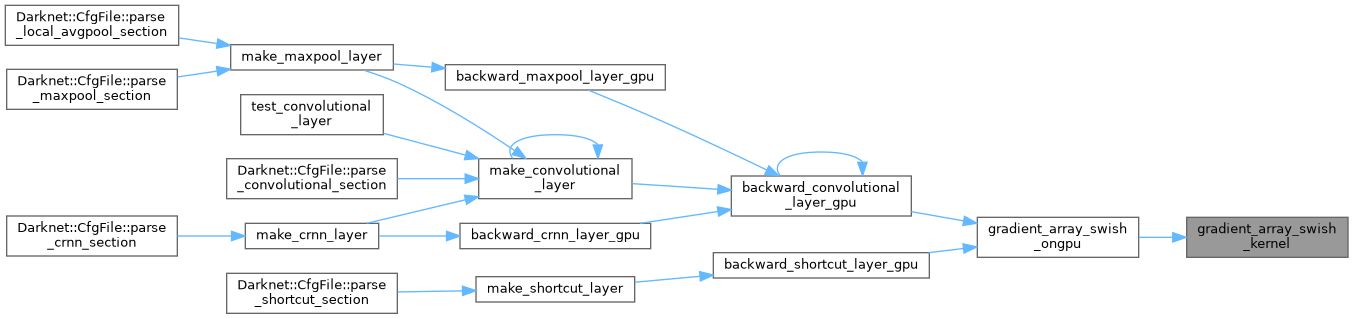
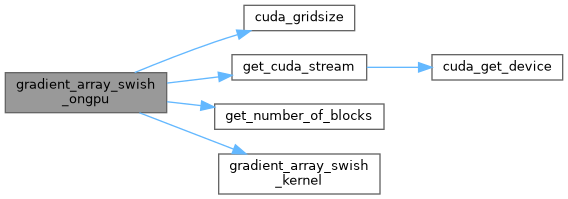
| void gradient_array_swish_ongpu | ( | float * | x, |
| int | n, | ||
| float * | sigmoid_gpu, | ||
| float * | delta | ||
| ) |
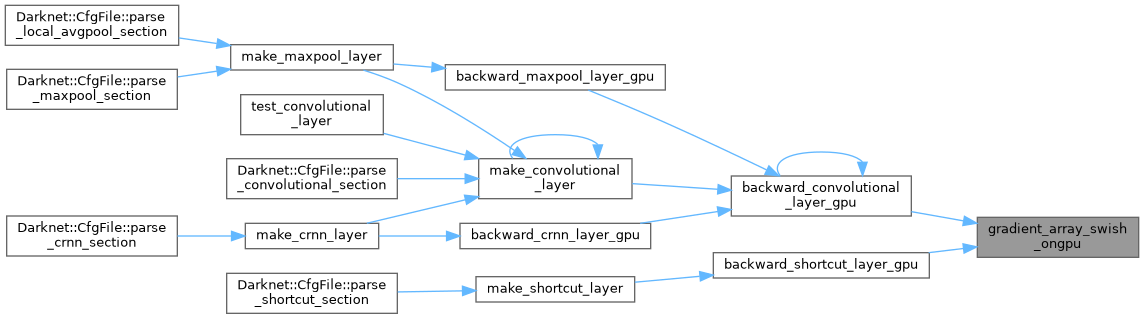
| __global__ void gradient_array_tanh_kernel | ( | float * | x, |
| int | n, | ||
| float * | delta | ||
| ) |

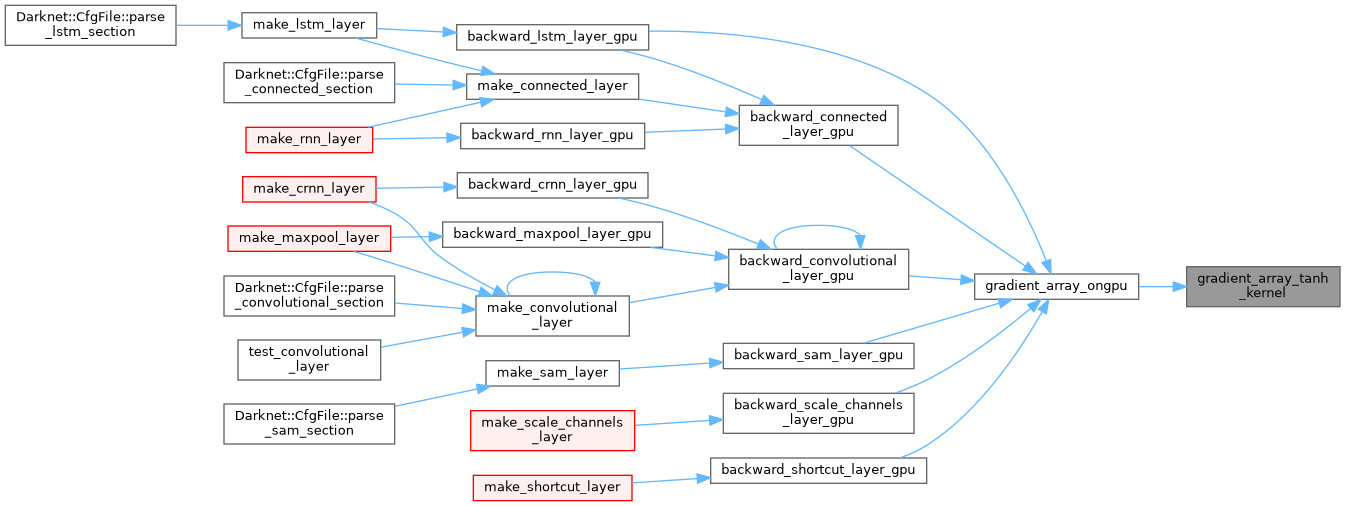
| __device__ float gradient_kernel | ( | float | x, |
| ACTIVATION | a | ||
| ) |
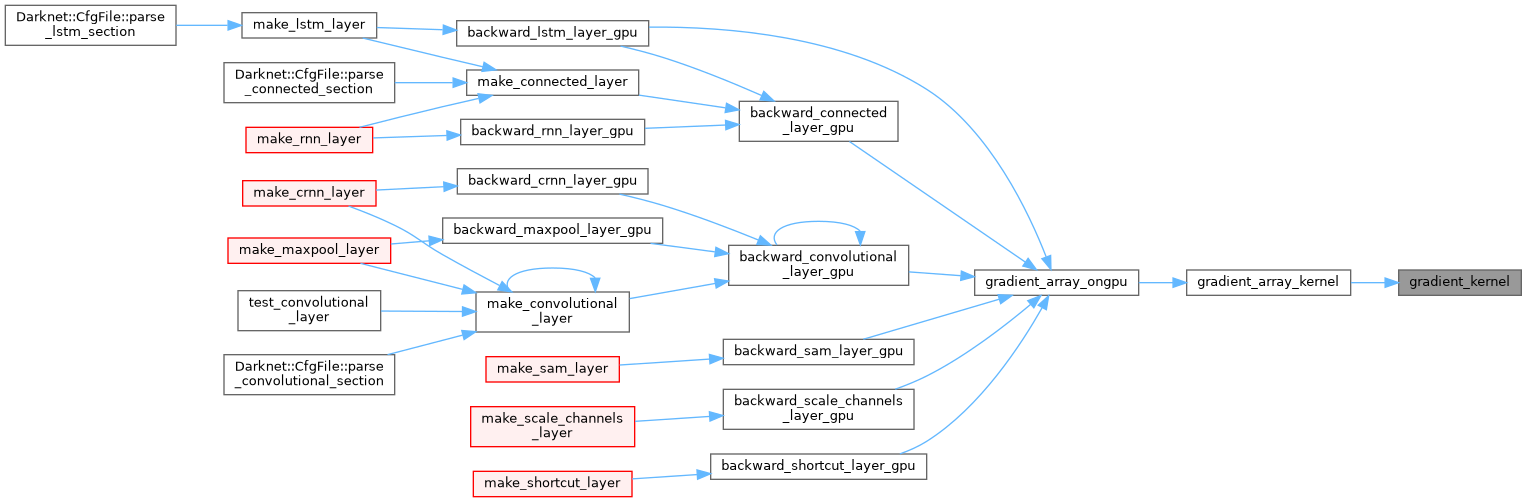
| __device__ float hard_mish_yashas | ( | float | x | ) |

| __device__ float hard_mish_yashas_grad | ( | float | x | ) |

| __device__ float hardtan_activate_kernel | ( | float | x | ) |
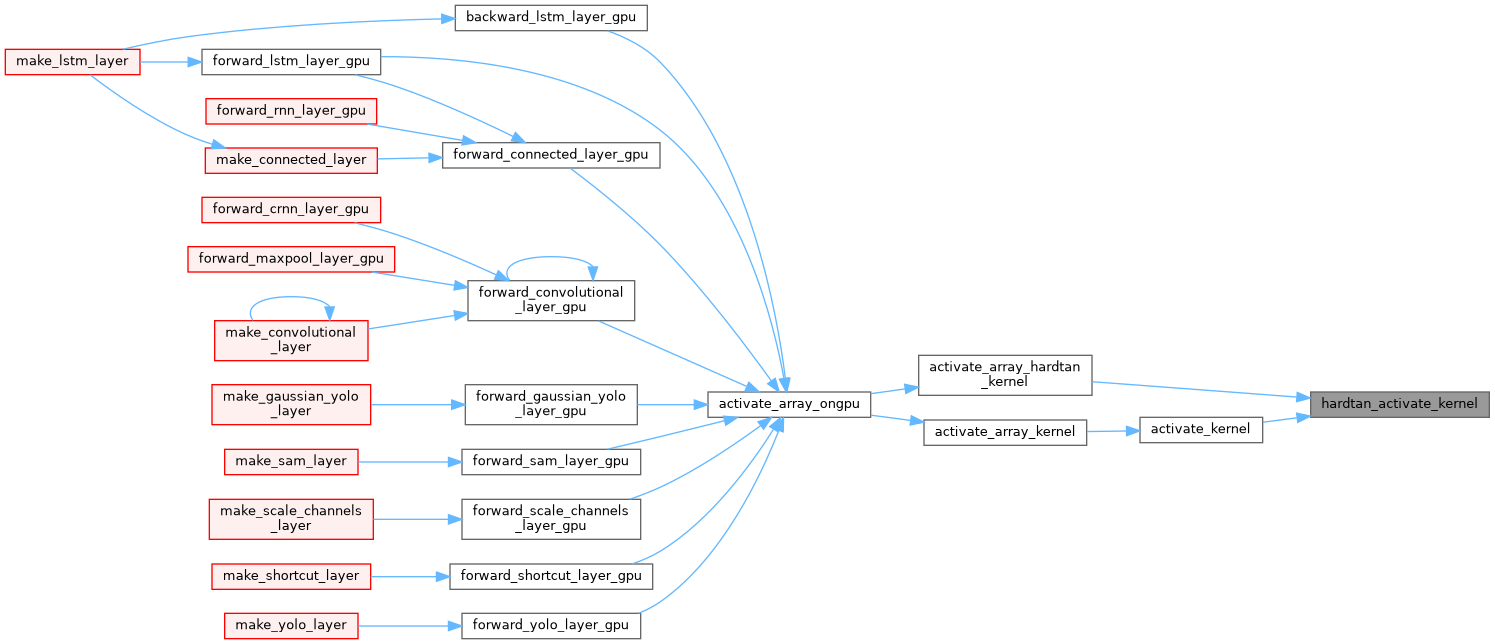
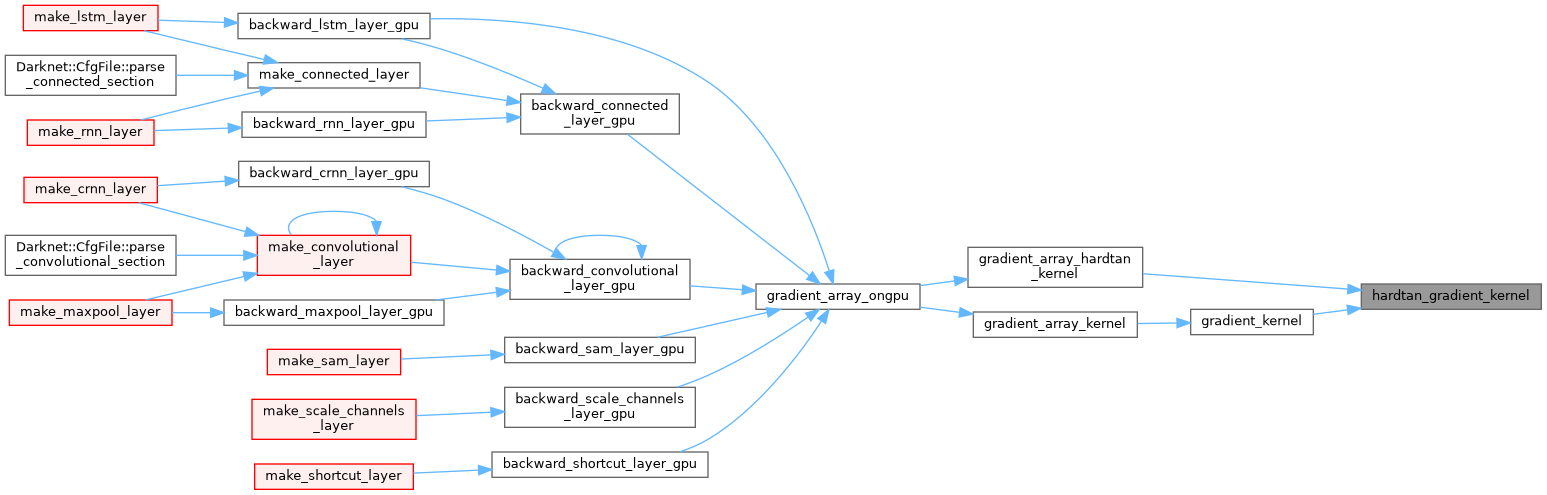
| __device__ float hardtan_gradient_kernel | ( | float | x | ) |
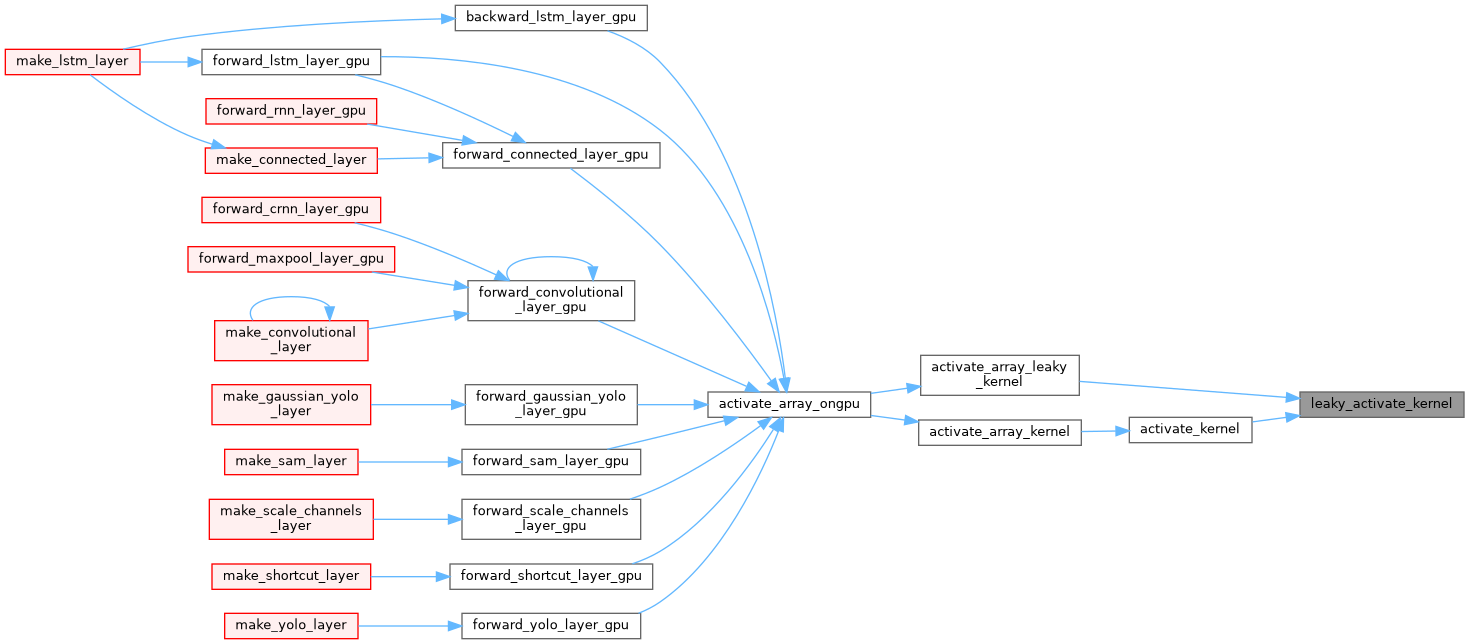
| __device__ float leaky_activate_kernel | ( | float | x | ) |
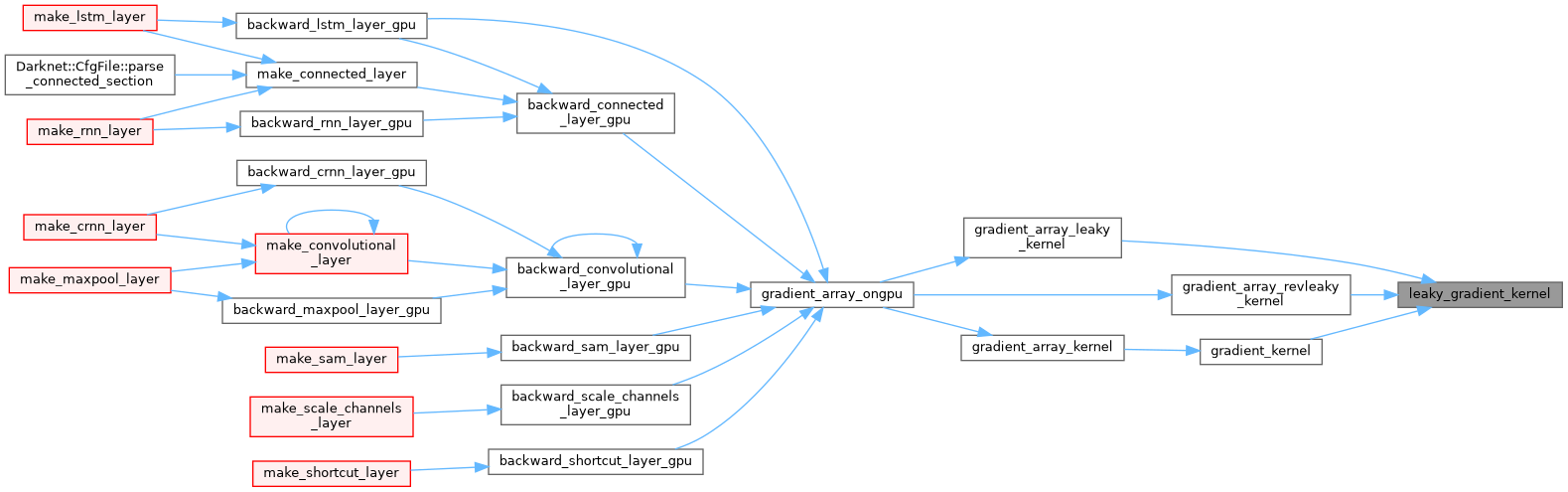
| __device__ float leaky_gradient_kernel | ( | float | x | ) |
| __device__ float lhtan_activate_kernel | ( | float | x | ) |
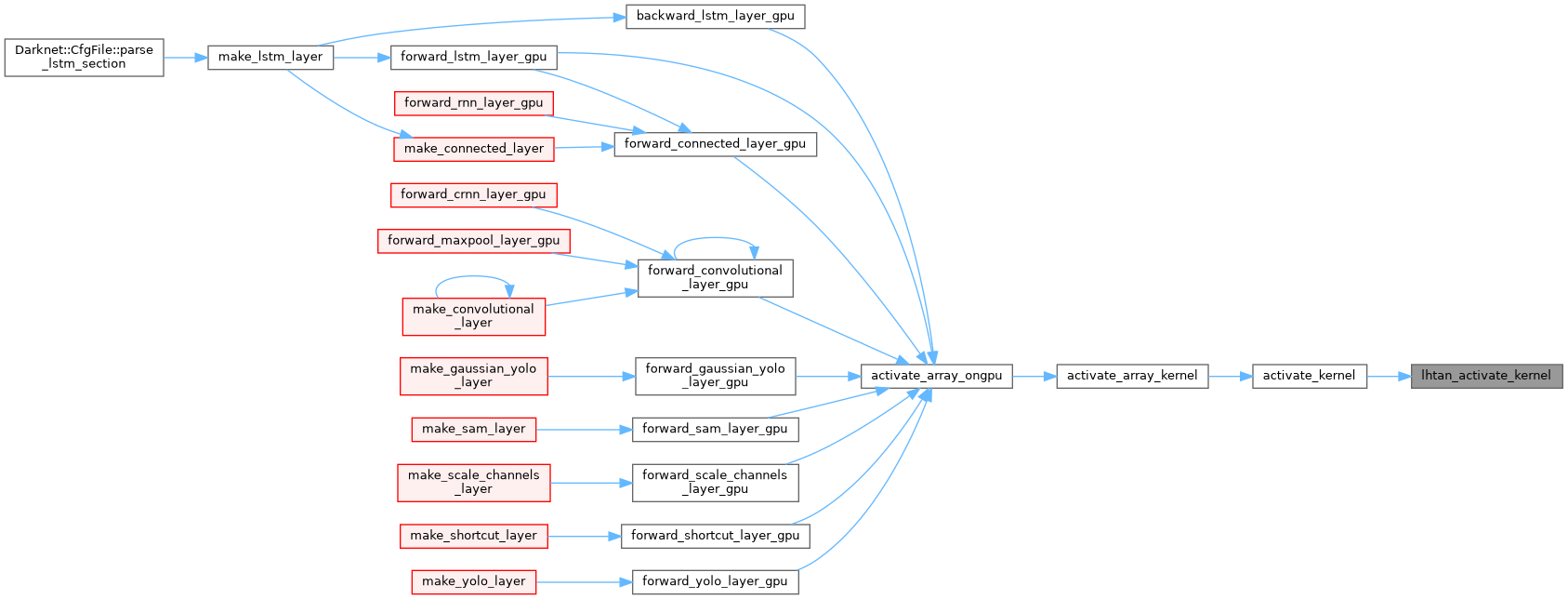
| __device__ float lhtan_gradient_kernel | ( | float | x | ) |
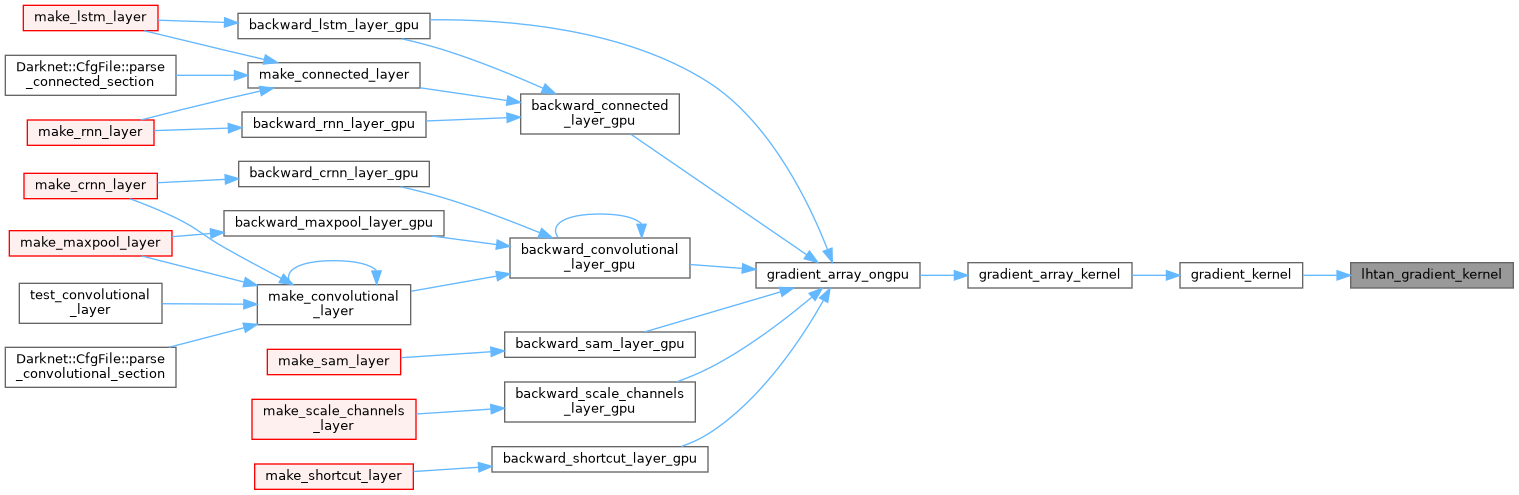
| __device__ float linear_activate_kernel | ( | float | x | ) |
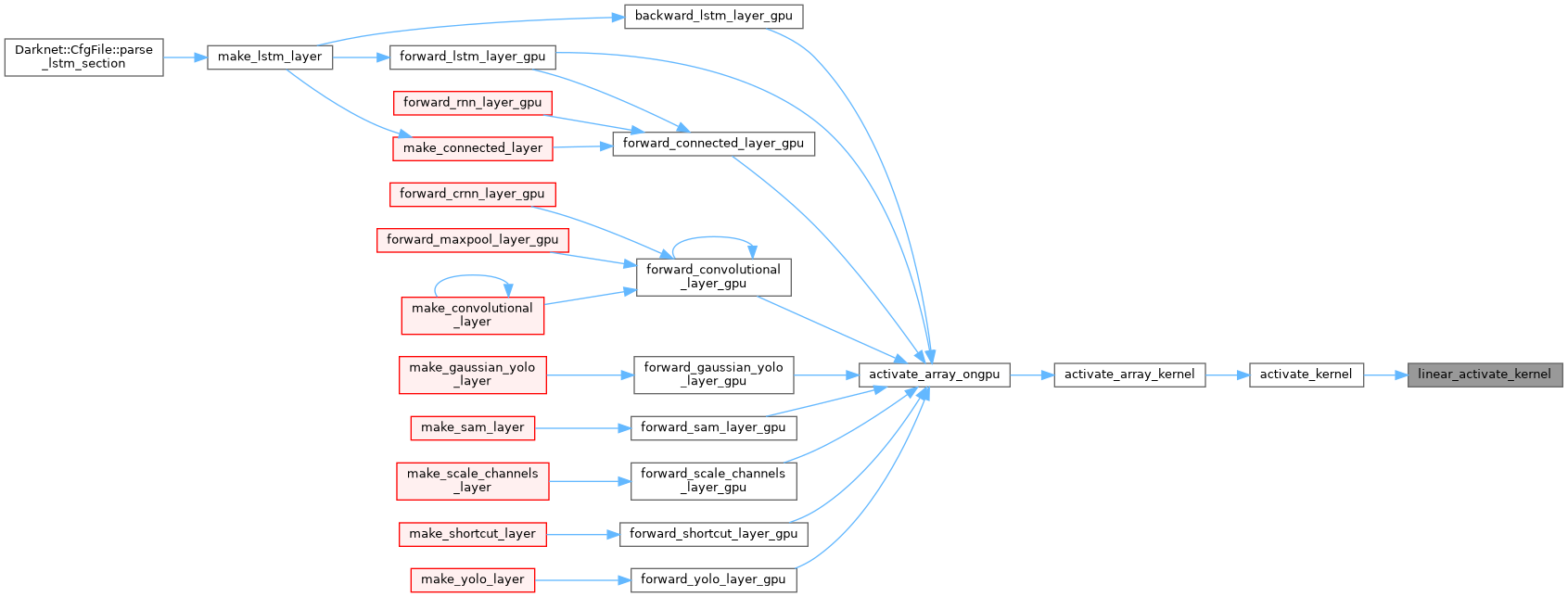
| __device__ float linear_gradient_kernel | ( | float | x | ) |
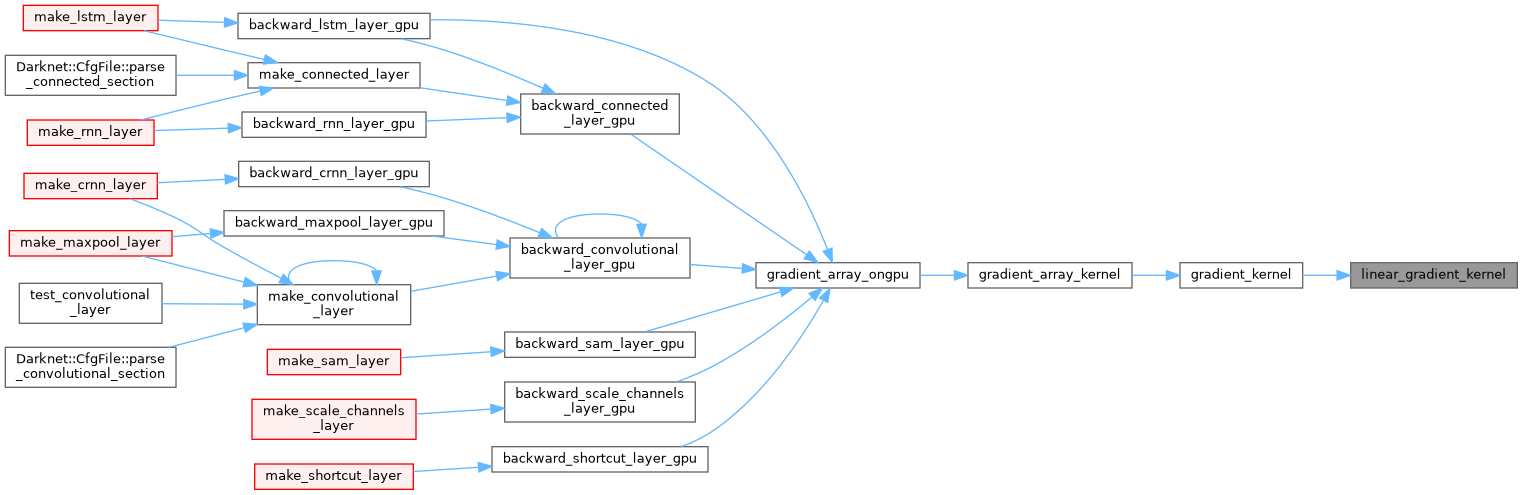
| __device__ float loggy_activate_kernel | ( | float | x | ) |
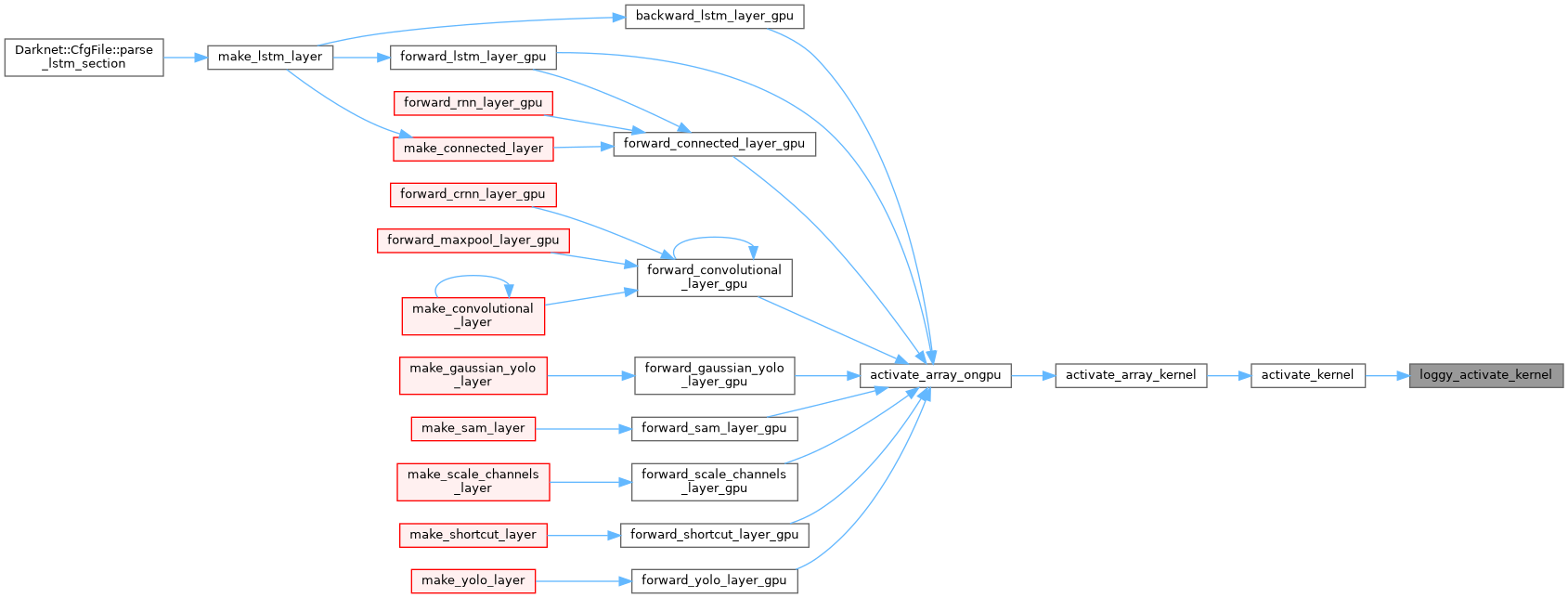
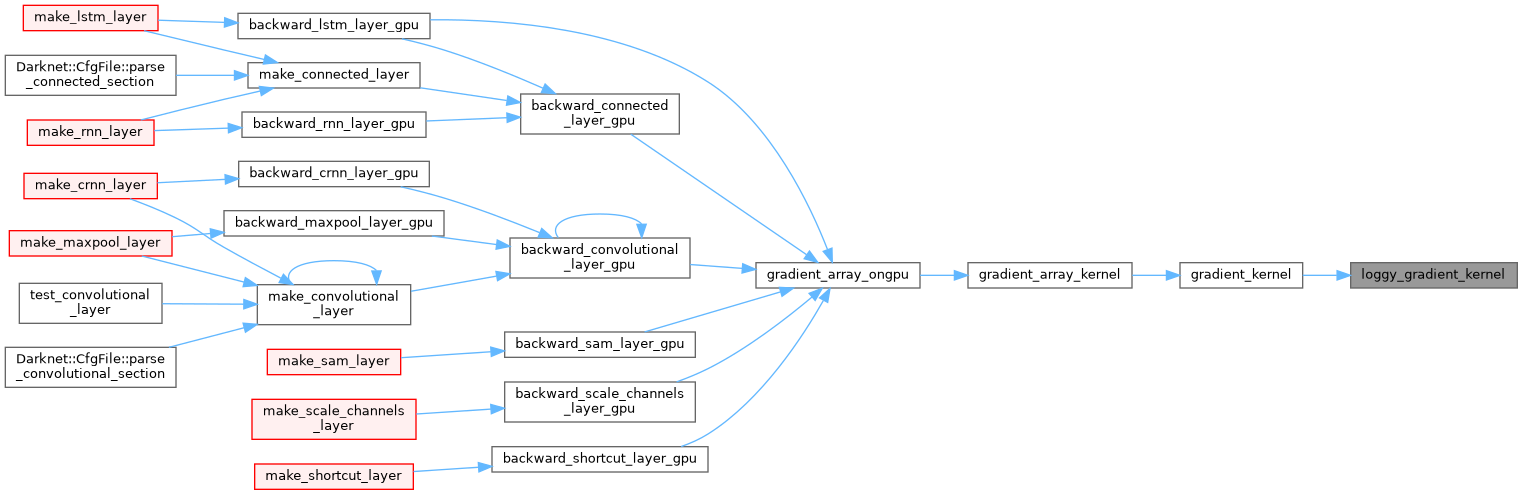
| __device__ float loggy_gradient_kernel | ( | float | x | ) |
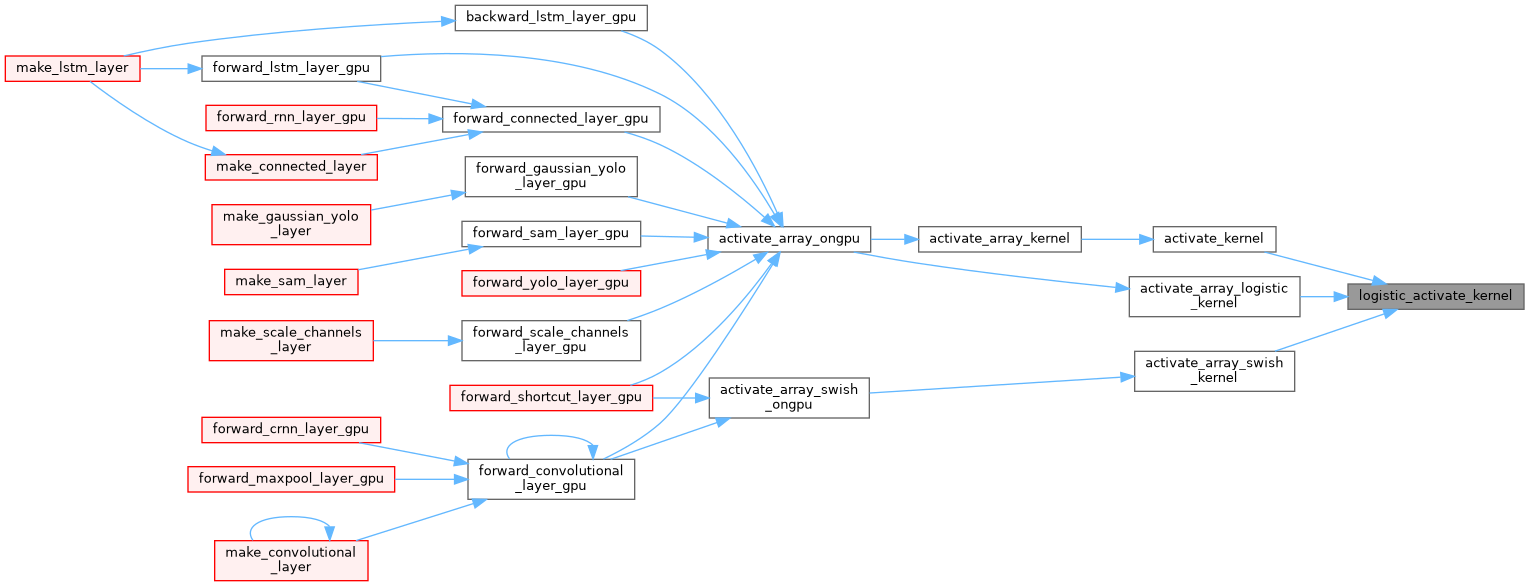
| __device__ float logistic_activate_kernel | ( | float | x | ) |
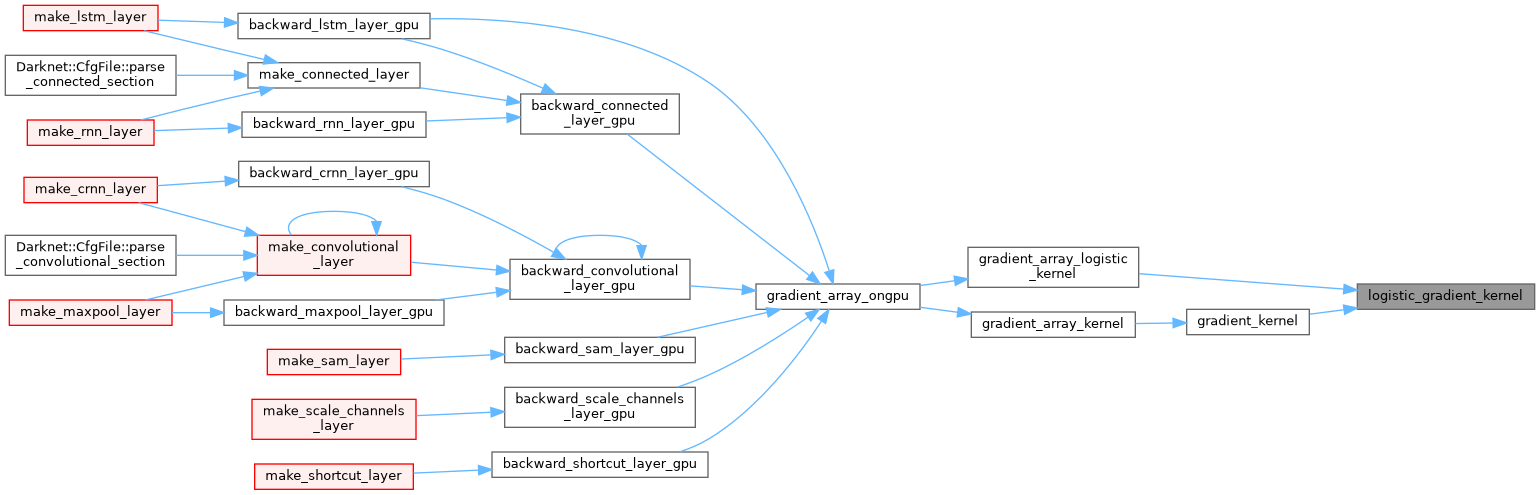
| __device__ float logistic_gradient_kernel | ( | float | x | ) |
| __device__ float mish_njuffa | ( | float | x | ) |
| __device__ float mish_yashas | ( | float | x | ) |
| __device__ float mish_yashas2 | ( | float | x | ) |
| __device__ float plse_activate_kernel | ( | float | x | ) |
| __device__ float plse_gradient_kernel | ( | float | x | ) |
| __device__ float ramp_activate_kernel | ( | float | x | ) |
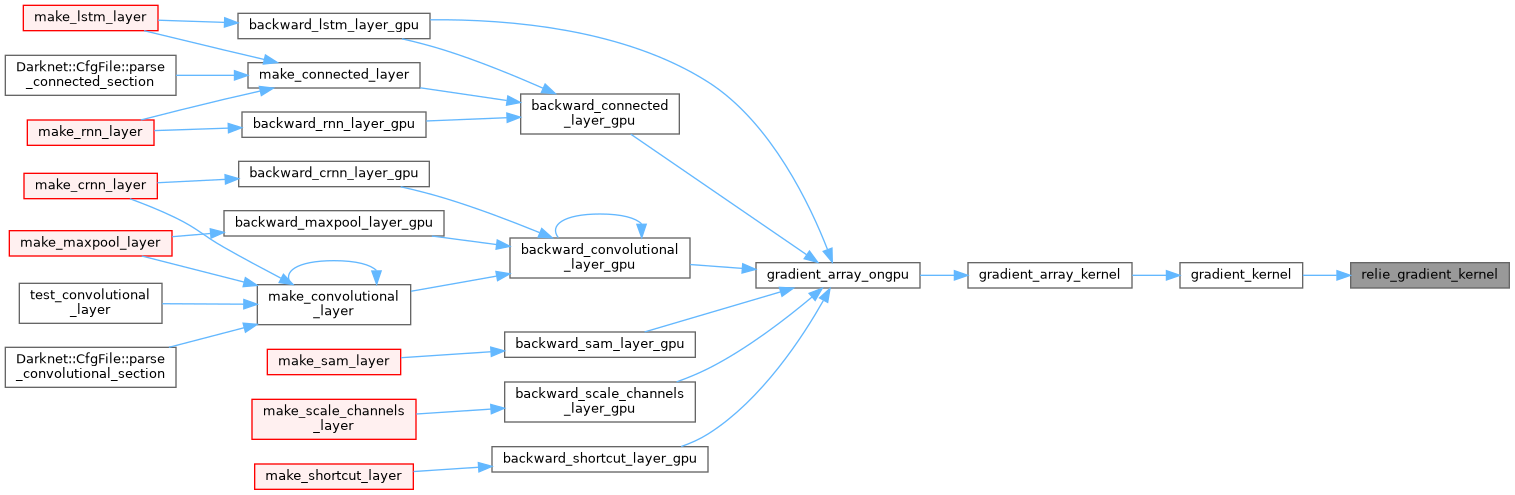
| __device__ float ramp_gradient_kernel | ( | float | x | ) |
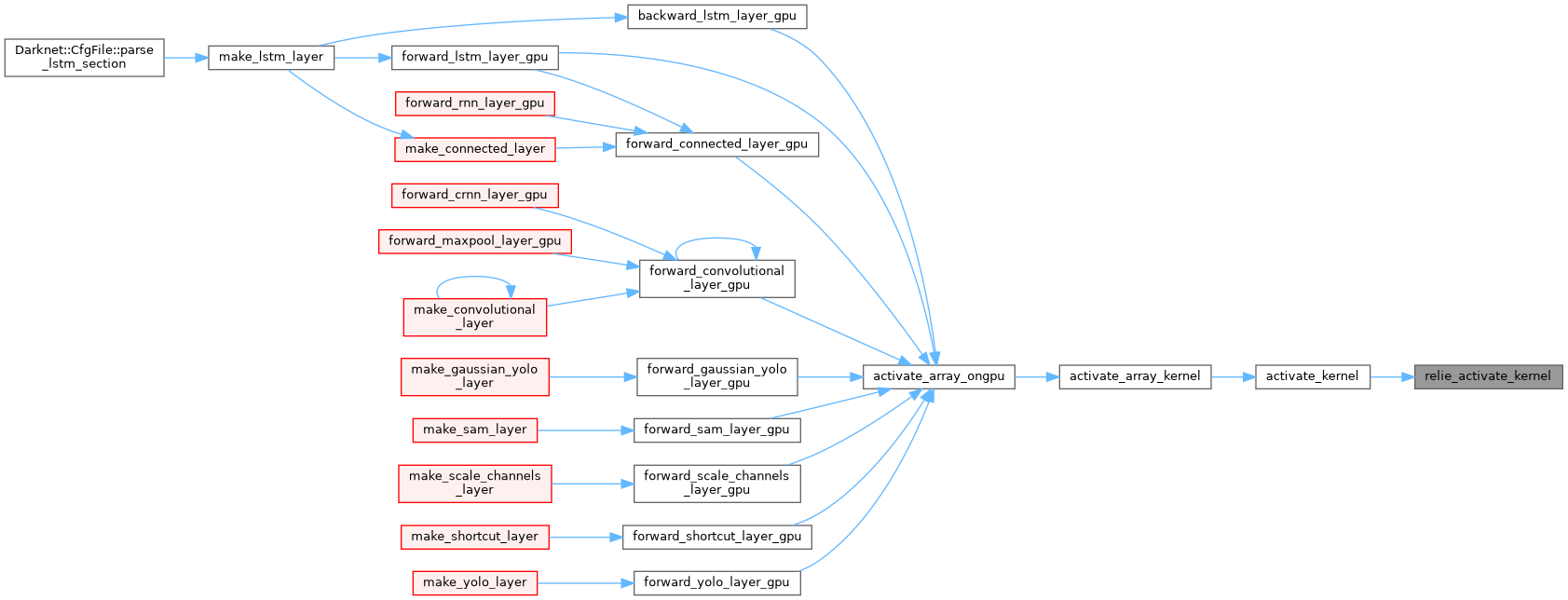
| __device__ float relie_activate_kernel | ( | float | x | ) |
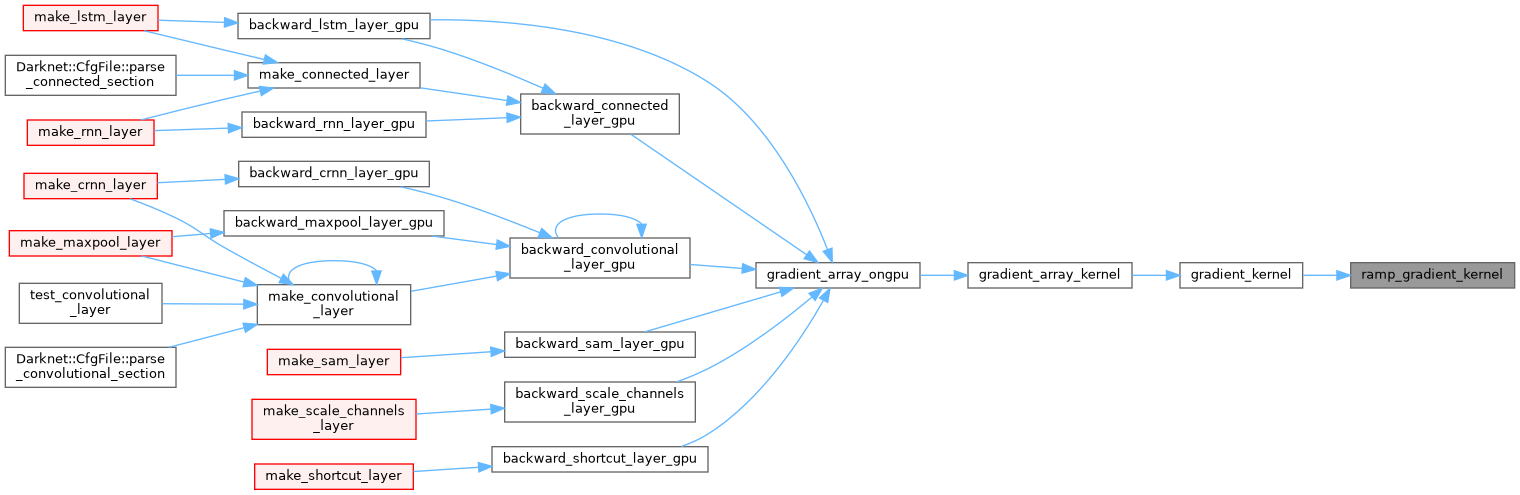
| __device__ float relie_gradient_kernel | ( | float | x | ) |
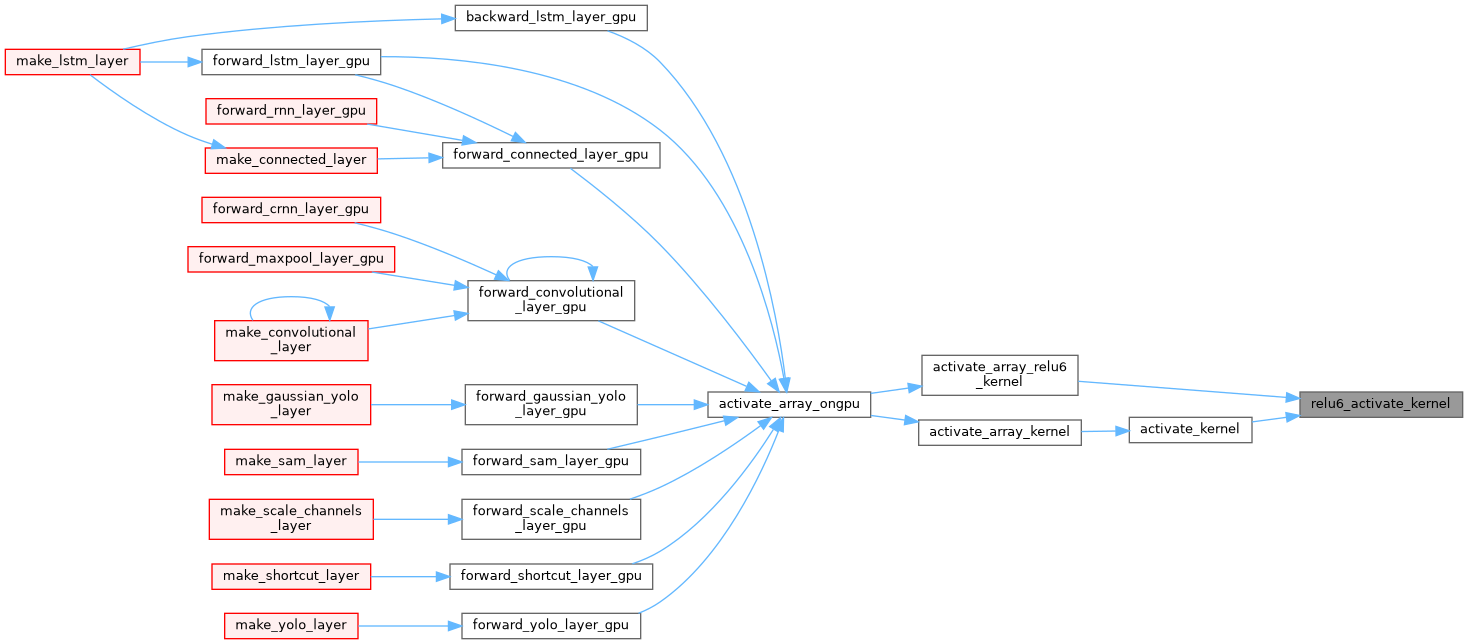
| __device__ float relu6_activate_kernel | ( | float | x | ) |
| __device__ float relu6_gradient_kernel | ( | float | x | ) |
| __device__ float relu_activate_kernel | ( | float | x | ) |
| __device__ float relu_gradient_kernel | ( | float | x | ) |
| __device__ float sech_gpu | ( | float | x | ) |
| __device__ float selu_activate_kernel | ( | float | x | ) |
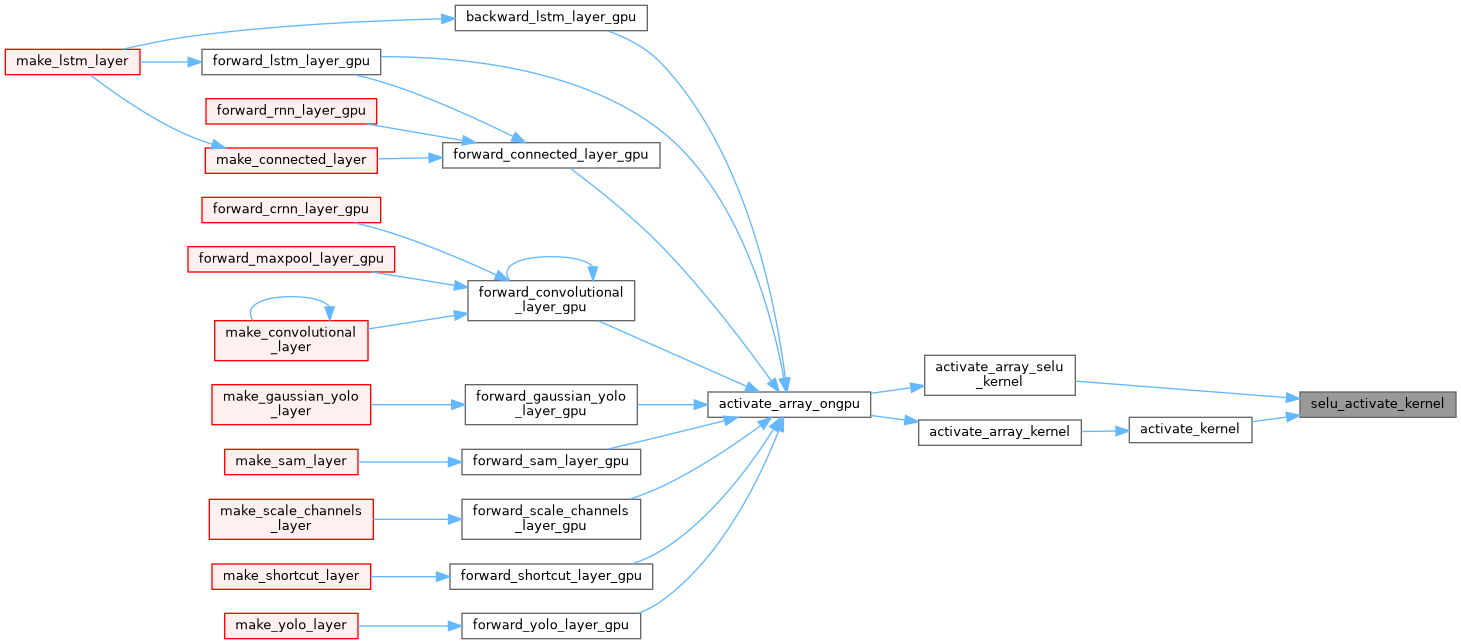
| __device__ float selu_gradient_kernel | ( | float | x | ) |
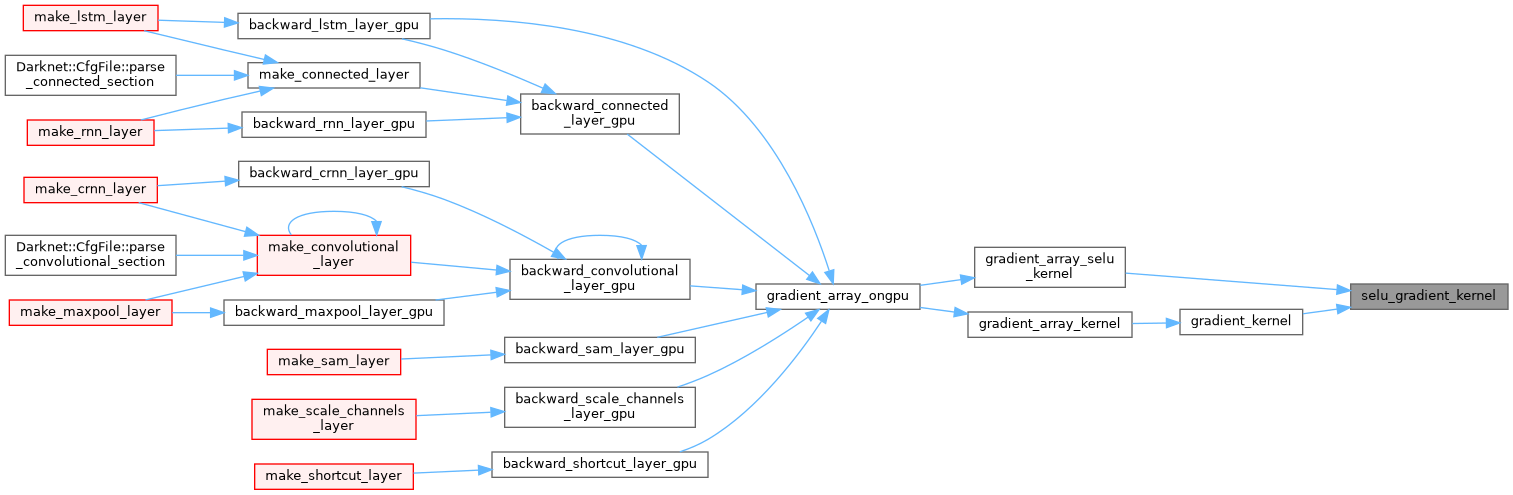
| __device__ float softplus_kernel | ( | float | x, |
| float | threshold = 20 |
||
| ) |
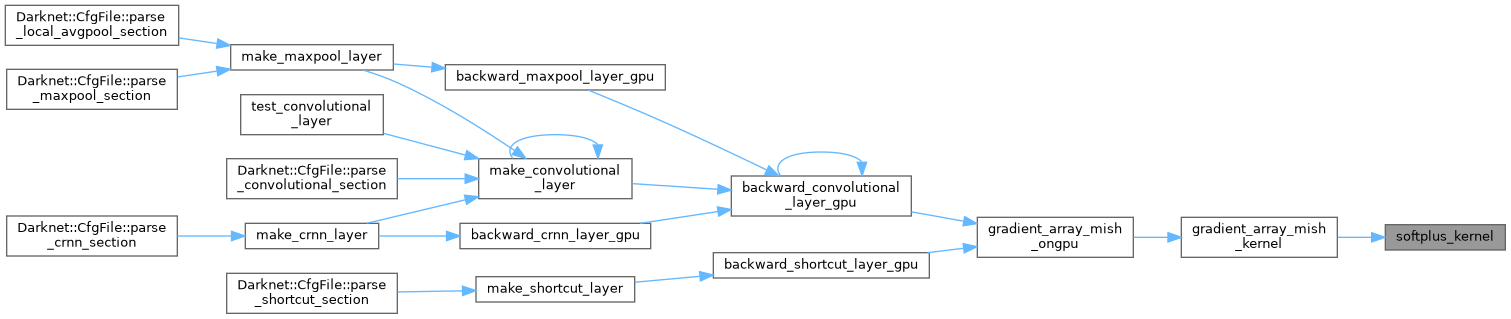
| __device__ float stair_activate_kernel | ( | float | x | ) |
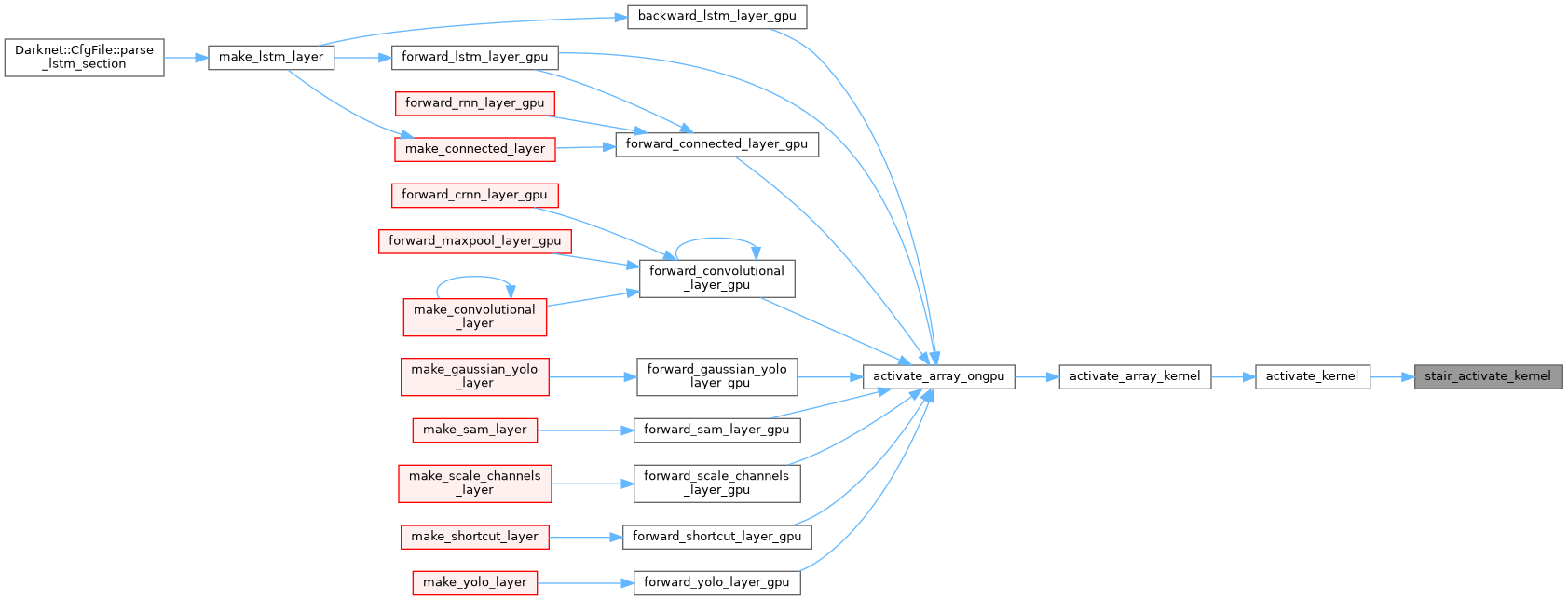
| __device__ float stair_gradient_kernel | ( | float | x | ) |
| __device__ float tanh_activate_kernel | ( | float | x | ) |
| __device__ float tanh_gradient_kernel | ( | float | x | ) |