|
Darknet/YOLO v5.0-41-g593bddc
Object Detection Framework
|

|
|
Darknet/YOLO v5.0-41-g593bddc
Object Detection Framework
|
|
Functions | |
| __global__ void | accumulate_kernel (float *x, int n, int groups, float *sum) |
| void | activate_and_mult (float *a1, float *a2, size_t size, ACTIVATION a, float *dst) |
| __global__ void | activate_and_mult_kernel (float *a1, float *a2, size_t size, ACTIVATION a, float *dst) |
| void | adam_gpu (int n, float *x, float *m, float *v, float B1, float B2, float rate, float eps, int t) |
| __global__ void | adam_kernel (int N, float *x, float *m, float *v, float B1, float B2, float rate, float eps, int t) |
| void | adam_update_gpu (float *w, float *d, float *m, float *v, float B1, float B2, float eps, float decay, float rate, int n, int batch, int t) |
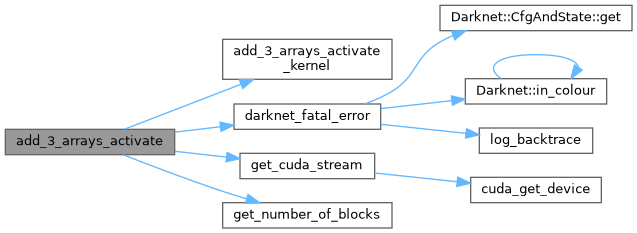
| void | add_3_arrays_activate (float *a1, float *a2, float *a3, size_t size, ACTIVATION a, float *dst) |
| __global__ void | add_3_arrays_activate_kernel (float *a1, float *a2, float *a3, size_t size, ACTIVATION a, float *dst) |
| void | add_bias_gpu (float *output, float *biases, int batch, int filters, int spatial) |
| __global__ void | add_bias_kernel (float *output, float *biases, int batch, int filters, int spatial, int current_size) |
| __global__ void | axpy_kernel (int N, float ALPHA, float *X, int OFFX, int INCX, float *Y, int OFFY, int INCY) |
| void | axpy_ongpu (int N, float ALPHA, float *X, int INCX, float *Y, int INCY) |
| void | axpy_ongpu_offset (int N, float ALPHA, float *X, int OFFX, int INCX, float *Y, int OFFY, int INCY) |
| void | backward_bias_gpu (float *bias_updates, float *delta, int batch, int n, int size) |
| __global__ void | backward_bias_kernel (float *bias_updates, float *delta, int batch, int n, int size) |
| void | backward_implicit_gpu (int batch, int nweights, float *weight_updates_gpu, float *delta_gpu) |
| __global__ void | backward_implicit_kernel (int size, int batch, int nweights, float *weight_updates_gpu, float *delta_gpu) |
| void | backward_sam_gpu (float *in_w_h_c_delta, int size, int channel_size, float *in_scales_c, float *out_from_delta, float *in_from_output, float *out_state_delta) |
| __global__ void | backward_sam_kernel (float *in_w_h_c_delta, int size, int channel_size, float *in_scales_c, float *out_from_delta, float *in_from_output, float *out_state_delta) |
| void | backward_scale_channels_gpu (float *in_w_h_c_delta, int size, int channel_size, int batch_size, int scale_wh, float *in_scales_c, float *out_from_delta, float *in_from_output, float *out_state_delta) |
| __global__ void | backward_scale_channels_kernel (float *in_w_h_c_delta, int size, int channel_size, int batch_size, int scale_wh, float *in_scales_c, float *out_from_delta, float *in_from_output, float *out_state_delta) |
| void | backward_scale_gpu (float *x_norm, float *delta, int batch, int n, int size, float *scale_updates) |
| __global__ void | backward_scale_kernel (float *x_norm, float *delta, int batch, int n, int size, float *scale_updates) |
| void | backward_shortcut_multilayer_gpu (int src_outputs, int batch, int n, int *outputs_of_layers_gpu, float **layers_delta_gpu, float *delta_out, float *delta_in, float *weights_gpu, float *weight_updates_gpu, int nweights, float *in, float **layers_output_gpu, WEIGHTS_NORMALIZATION_T weights_normalization) |
| __global__ void | backward_shortcut_multilayer_kernel (int size, int src_outputs, int batch, int n, int *outputs_of_layers_gpu, float **layers_delta_gpu, float *delta_out, float *delta_in, float *weights_gpu, float *weight_updates_gpu, int nweights, float *in, float **layers_output_gpu, WEIGHTS_NORMALIZATION_T weights_normalization) |
| __global__ void | const_kernel (int N, float ALPHA, float *X, int INCX) |
| void | const_ongpu (int N, float ALPHA, float *X, int INCX) |
| __global__ void | constrain_kernel (int N, float ALPHA, float *X, int INCX) |
| __global__ void | constrain_min_max_kernel (int N, float MIN, float MAX, float *X, int INCX) |
| void | constrain_min_max_ongpu (int N, float MIN, float MAX, float *X, int INCX) |
| void | constrain_ongpu (int N, float ALPHA, float *X, int INCX) |
| __global__ void | constrain_weight_updates_kernel (int N, float coef, float *weights_gpu, float *weight_updates_gpu) |
| void | constrain_weight_updates_ongpu (int N, float coef, float *weights_gpu, float *weight_updates_gpu) |
| void | coord_conv_gpu (float *dst, int size, int w, int h, int chan, int b, int type) |
| __global__ void | coord_conv_kernel (float *dst, int w, int h, int chan, int batch, int type) |
| __global__ void | copy_kernel (int N, float *X, int OFFX, int INCX, float *Y, int OFFY, int INCY) |
| void | copy_ongpu (int N, float *X, int INCX, float *Y, int INCY) |
| void | copy_ongpu_offset (int N, float *X, int OFFX, int INCX, float *Y, int OFFY, int INCY) |
| void | expand_array_gpu (const float *src_gpu, float *dst_gpu, int size, int groups) |
| __global__ void | expand_array_kernel (const float *src_gpu, float *dst_gpu, int current_size, int groups) |
| void | fast_mean_delta_gpu (float *delta, float *variance, int batch, int filters, int spatial, float *mean_delta) |
| __global__ void | fast_mean_delta_kernel (float *delta, float *variance, int batch, int filters, int spatial, float *mean_delta) |
| void | fast_mean_gpu (float *x, int batch, int filters, int spatial, float *mean) |
| __global__ void | fast_mean_kernel (float *x, int batch, int filters, int spatial, float *mean) |
| void | fast_v_cbn_gpu (const float *x, float *mean, int batch, int filters, int spatial, int minibatch_index, int max_minibatch_index, float *m_avg, float *v_avg, float *variance, const float alpha, float *rolling_mean_gpu, float *rolling_variance_gpu, int inverse_variance, float epsilon) |
| __global__ void | fast_v_cbn_kernel (const float *x, float *mean, int batch, int filters, int spatial, int minibatch_index, int max_minibatch_index, float *m_avg, float *v_avg, float *variance, const float alpha, float *rolling_mean_gpu, float *rolling_variance_gpu, int inverse_variance, float epsilon) |
| void | fast_variance_delta_gpu (float *x, float *delta, float *mean, float *variance, int batch, int filters, int spatial, float *variance_delta) |
| __global__ void | fast_variance_delta_kernel (float *x, float *delta, float *mean, float *variance, int batch, int filters, int spatial, float *variance_delta) |
| void | fast_variance_gpu (float *x, float *mean, int batch, int filters, int spatial, float *variance) |
| __global__ void | fast_variance_kernel (float *x, float *mean, int batch, int filters, int spatial, float *variance) |
| __global__ void | fill_kernel (int N, float ALPHA, float *X, int INCX) |
| void | fill_ongpu (int N, float ALPHA, float *X, int INCX) |
| void | fix_nan_and_inf (float *input, size_t size) |
| __global__ void | fix_nan_and_inf_kernel (float *input, size_t size) |
| __global__ void | flatten_kernel (int N, float *x, int spatial, int layers, int batch, int forward, float *out) |
| void | flatten_ongpu (float *x, int spatial, int layers, int batch, int forward, float *out) |
| void | forward_implicit_gpu (int batch, int nweights, float *weight_gpu, float *output_gpu) |
| __global__ void | forward_implicit_kernel (int size, int batch, int nweights, float *weight_gpu, float *output_gpu) |
| __device__ float | grad_lrelu (float src) |
| __device__ float | grad_relu (float src) |
| void | gradient_centralization_gpu (int w, int h, int c, int f, float *in) |
| __global__ void | gradient_centralization_kernel (int filters, int f_size, float *in) |
| void | input_shortcut_gpu (float *in, int batch, int w1, int h1, int c1, float *add, int w2, int h2, int c2, float *out) |
| __global__ void | input_shortcut_kernel (float *in, int size, int minw, int minh, int minc, int stride, int sample, int batch, int w1, int h1, int c1, float *add, int w2, int h2, int c2, float *out) |
| __global__ void | inverse_variance_kernel (int size, float *src, float *dst, float epsilon) |
| void | inverse_variance_ongpu (int size, float *src, float *dst, float epsilon) |
| int | is_nan_or_inf (float *input, size_t size) |
| __global__ void | is_nan_or_inf_kernel (float *input, size_t size, int *pinned_return) |
| void | l2_gpu (int n, float *pred, float *truth, float *delta, float *error) |
| __global__ void | l2_kernel (int n, float *pred, float *truth, float *delta, float *error) |
| __device__ float | lrelu (float src) |
| void | mask_gpu_new_api (int N, float *X, float mask_num, float *mask, float val) |
| __global__ void | mask_kernel (int n, float *x, float mask_num, float *mask) |
| __global__ void | mask_kernel_new_api (int n, float *x, float mask_num, float *mask, float val) |
| void | mask_ongpu (int N, float *X, float mask_num, float *mask) |
| void | mean_array_gpu (float *src, int size, float alpha, float *avg) |
| __global__ void | mean_array_kernel (float *src, int size, float alpha, float *avg) |
| void | mean_delta_gpu (float *delta, float *variance, int batch, int filters, int spatial, float *mean_delta) |
| __global__ void | mean_delta_kernel (float *delta, float *variance, int batch, int filters, int spatial, float *mean_delta) |
| void | mean_gpu (float *x, int batch, int filters, int spatial, float *mean) |
| __global__ void | mean_kernel (float *x, int batch, int filters, int spatial, float *mean) |
| void | memcpy_ongpu (void *dst, void *src, int size_bytes) |
| __global__ void | mul_kernel (int N, float *X, int INCX, float *Y, int INCY) |
| void | mul_ongpu (int N, float *X, int INCX, float *Y, int INCY) |
| void | mult_add_into_gpu (int num, float *a, float *b, float *c) |
| __global__ void | mult_add_into_kernel (int n, float *a, float *b, float *c) |
| void | mult_inverse_array_gpu (const float *src_gpu, float *dst_gpu, int size, float eps, float divider, float clip, float abs_add) |
| __global__ void | mult_inverse_array_kernel (const float *src_gpu, float *dst_gpu, int size, const float eps, float divider, const float clip, const float abs_add) |
| void | normalize_delta_gpu (float *x, float *mean, float *variance, float *mean_delta, float *variance_delta, int batch, int filters, int spatial, float *delta) |
| __global__ void | normalize_delta_kernel (int N, float *x, float *mean, float *variance, float *mean_delta, float *variance_delta, int batch, int filters, int spatial, float *delta) |
| void | normalize_gpu (float *x, float *mean, float *variance, int batch, int filters, int spatial) |
| __global__ void | normalize_kernel (int N, float *x, float *mean, float *variance, int batch, int filters, int spatial) |
| void | normalize_scale_bias_gpu (float *x, float *mean, float *variance, float *scales, float *biases, int batch, int filters, int spatial, int inverse_variance, float epsilon) |
| __global__ void | normalize_scale_bias_kernel (int N, float *x, float *mean, float *variance, float *scales, float *biases, int batch, int filters, int spatial, int inverse_variance, float epsilon) |
| void | P_constrastive_f_det_gpu (int *labels, unsigned int feature_size, float temperature, contrastive_params *contrast_p, const int contrast_p_size) |
| __global__ void | P_constrastive_f_det_kernel (int *labels, unsigned int feature_size, float temperature, contrastive_params *contrast_p, const int contrast_p_size) |
| __global__ void | pow_kernel (int N, float ALPHA, float *X, int INCX, float *Y, int INCY) |
| void | pow_ongpu (int N, float ALPHA, float *X, int INCX, float *Y, int INCY) |
| void | reduce_and_expand_array_gpu (const float *src_gpu, float *dst_gpu, int size, int groups) |
| __global__ void | reduce_and_expand_array_kernel (const float *src_gpu, float *dst_gpu, int current_size, int groups) |
| __device__ float | relu (float src) |
| __global__ void | reorg_kernel (int N, float *x, int w, int h, int c, int batch, int stride, int forward, float *out) |
| void | reorg_ongpu (float *x, int w, int h, int c, int batch, int stride, int forward, float *out) |
| void | reset_nan_and_inf (float *input, size_t size) |
| __global__ void | reset_nan_and_inf_kernel (float *input, size_t size) |
| void | rotate_weights_gpu (const float *src_weight_gpu, float *weight_deform_gpu, int nweights, int n, int size, int reverse) |
| __global__ void | rotate_weights_kernel (const float *src_weight_gpu, float *weight_deform_gpu, int nweights, int n, int kernel_size, int reverse) |
| void | sam_gpu (float *in_w_h_c, int size, int channel_size, float *scales_c, float *out) |
| __global__ void | sam_kernel (float *in_w_h_c, int size, int channel_size, float *scales_c, float *out) |
| __global__ void | scal_add_kernel (int N, float ALPHA, float BETA, float *X, int INCX) |
| void | scal_add_ongpu (int N, float ALPHA, float BETA, float *X, int INCX) |
| __global__ void | scal_kernel (int N, float ALPHA, float *X, int INCX) |
| void | scal_ongpu (int N, float ALPHA, float *X, int INCX) |
| void | scale_bias_gpu (float *output, float *scale, int batch, int filters, int spatial) |
| __global__ void | scale_bias_kernel (float *output, float *scale, int batch, int filters, int spatial, int current_size) |
| void | scale_channels_gpu (float *in_w_h_c, int size, int channel_size, int batch_size, int scale_wh, float *scales_c, float *out) |
| __global__ void | scale_channels_kernel (float *in_w_h_c, int size, int channel_size, int batch_size, int scale_wh, float *scales_c, float *out) |
| void | shortcut_gpu (int batch, int w1, int h1, int c1, float *add, int w2, int h2, int c2, float *out) |
| __global__ void | shortcut_kernel (int size, int minw, int minh, int minc, int stride, int sample, int batch, int w1, int h1, int c1, float *add, int w2, int h2, int c2, float *out) |
| void | shortcut_multilayer_gpu (int src_outputs, int batch, int n, int *outputs_of_layers_gpu, float **layers_output_gpu, float *out, float *in, float *weights_gpu, int nweights, WEIGHTS_NORMALIZATION_T weights_normalization) |
| __global__ void | shortcut_multilayer_kernel (int size, int src_outputs, int batch, int n, int *outputs_of_layers_gpu, float **layers_output_gpu, float *out, float *in, float *weights_gpu, int nweights, WEIGHTS_NORMALIZATION_T weights_normalization) |
| __global__ void | shortcut_singlelayer_simple_kernel (int size, int src_outputs, int batch, int n, int *outputs_of_layers_gpu, float **layers_output_gpu, float *out, float *in, float *weights_gpu, int nweights, WEIGHTS_NORMALIZATION_T weights_normalization) |
| __global__ void | simple_copy_kernel (int size, float *src, float *dst) |
| void | simple_copy_ongpu (int size, float *src, float *dst) |
| __global__ void | simple_input_shortcut_kernel (float *in, int size, float *add, float *out) |
| void | smooth_l1_gpu (int n, float *pred, float *truth, float *delta, float *error) |
| __global__ void | smooth_l1_kernel (int n, float *pred, float *truth, float *delta, float *error) |
| void | smooth_rotate_weights_gpu (const float *src_weight_gpu, float *weight_deform_gpu, int nweights, int n, int size, int angle, int reverse) |
| __global__ void | smooth_rotate_weights_kernel (const float *src_weight_gpu, float *weight_deform_gpu, int nweights, int n, int kernel_size, int angle, int reverse) |
| __device__ void | softmax_device (int n, float *input, float temp, float *output) |
| __device__ void | softmax_device_new_api (float *input, int n, float temp, int stride, float *output) |
| void | softmax_gpu (float *input, int n, int offset, int groups, float temp, float *output) |
| void | softmax_gpu_new_api (float *input, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float *output) |
| __global__ void | softmax_kernel (int n, int offset, int batch, float *input, float temp, float *output) |
| __global__ void | softmax_kernel_new_api (float *input, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float *output) |
| void | softmax_tree_gpu (float *input, int spatial, int batch, int stride, float temp, float *output, Darknet::Tree hier) |
| __global__ void | softmax_tree_kernel (float *input, int spatial, int batch, int stride, float temp, float *output, int groups, int *group_size, int *group_offset) |
| void | softmax_x_ent_gpu (int n, float *pred, float *truth, float *delta, float *error) |
| __global__ void | softmax_x_ent_kernel (int n, float *pred, float *truth, float *delta, float *error) |
| void | stretch_sway_flip_weights_gpu (const float *src_weight_gpu, float *weight_deform_gpu, int nweights, int n, int size, int angle, int reverse) |
| __global__ void | stretch_sway_flip_weights_kernel (const float *src_weight_gpu, float *weight_deform_gpu, int nweights, int n, int kernel_size, float angle, int reverse) |
| void | stretch_weights_gpu (const float *src_weight_gpu, float *weight_deform_gpu, int nweights, int n, int size, float scale, int reverse) |
| __global__ void | stretch_weights_kernel (const float *src_weight_gpu, float *weight_deform_gpu, int nweights, int n, int kernel_size, float scale, int reverse) |
| void | sum_of_mults (float *a1, float *a2, float *b1, float *b2, size_t size, float *dst) |
| __global__ void | sum_of_mults_kernel (float *a1, float *a2, float *b1, float *b2, size_t size, float *dst) |
| __global__ void | supp_kernel (int N, float ALPHA, float *X, int INCX) |
| void | supp_ongpu (int N, float ALPHA, float *X, int INCX) |
| void | sway_and_flip_weights_gpu (const float *src_weight_gpu, float *weight_deform_gpu, int nweights, int n, int size, int angle, int reverse) |
| __global__ void | sway_and_flip_weights_kernel (const float *src_weight_gpu, float *weight_deform_gpu, int nweights, int n, int kernel_size, int angle, int reverse) |
| void | upsample_gpu (float *in, int w, int h, int c, int batch, int stride, int forward, float scale, float *out) |
| __global__ void | upsample_kernel (size_t N, float *x, int w, int h, int c, int batch, int stride, int forward, float scale, float *out) |
| __global__ void | variance_delta_kernel (float *x, float *delta, float *mean, float *variance, int batch, int filters, int spatial, float *variance_delta) |
| void | variance_gpu (float *x, float *mean, int batch, int filters, int spatial, float *variance) |
| __global__ void | variance_kernel (float *x, float *mean, int batch, int filters, int spatial, float *variance) |
| __inline__ __device__ float | warpAllReduceSum (float val) |
| void | weighted_delta_gpu (float *a, float *b, float *s, float *da, float *db, float *ds, int num, float *dc) |
| __global__ void | weighted_delta_kernel (int n, float *a, float *b, float *s, float *da, float *db, float *ds, float *dc) |
| void | weighted_sum_gpu (float *a, float *b, float *s, int num, float *c) |
| __global__ void | weighted_sum_kernel (int n, float *a, float *b, float *s, float *c) |
| __global__ void accumulate_kernel | ( | float * | x, |
| int | n, | ||
| int | groups, | ||
| float * | sum | ||
| ) |
| void activate_and_mult | ( | float * | a1, |
| float * | a2, | ||
| size_t | size, | ||
| ACTIVATION | a, | ||
| float * | dst | ||
| ) |
| __global__ void activate_and_mult_kernel | ( | float * | a1, |
| float * | a2, | ||
| size_t | size, | ||
| ACTIVATION | a, | ||
| float * | dst | ||
| ) |

| void adam_gpu | ( | int | n, |
| float * | x, | ||
| float * | m, | ||
| float * | v, | ||
| float | B1, | ||
| float | B2, | ||
| float | rate, | ||
| float | eps, | ||
| int | t | ||
| ) |
| __global__ void adam_kernel | ( | int | N, |
| float * | x, | ||
| float * | m, | ||
| float * | v, | ||
| float | B1, | ||
| float | B2, | ||
| float | rate, | ||
| float | eps, | ||
| int | t | ||
| ) |

| void adam_update_gpu | ( | float * | w, |
| float * | d, | ||
| float * | m, | ||
| float * | v, | ||
| float | B1, | ||
| float | B2, | ||
| float | eps, | ||
| float | decay, | ||
| float | rate, | ||
| int | n, | ||
| int | batch, | ||
| int | t | ||
| ) |
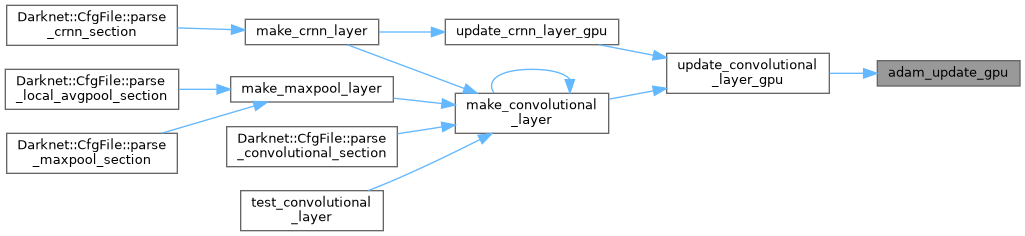
| void add_3_arrays_activate | ( | float * | a1, |
| float * | a2, | ||
| float * | a3, | ||
| size_t | size, | ||
| ACTIVATION | a, | ||
| float * | dst | ||
| ) |
| __global__ void add_3_arrays_activate_kernel | ( | float * | a1, |
| float * | a2, | ||
| float * | a3, | ||
| size_t | size, | ||
| ACTIVATION | a, | ||
| float * | dst | ||
| ) |

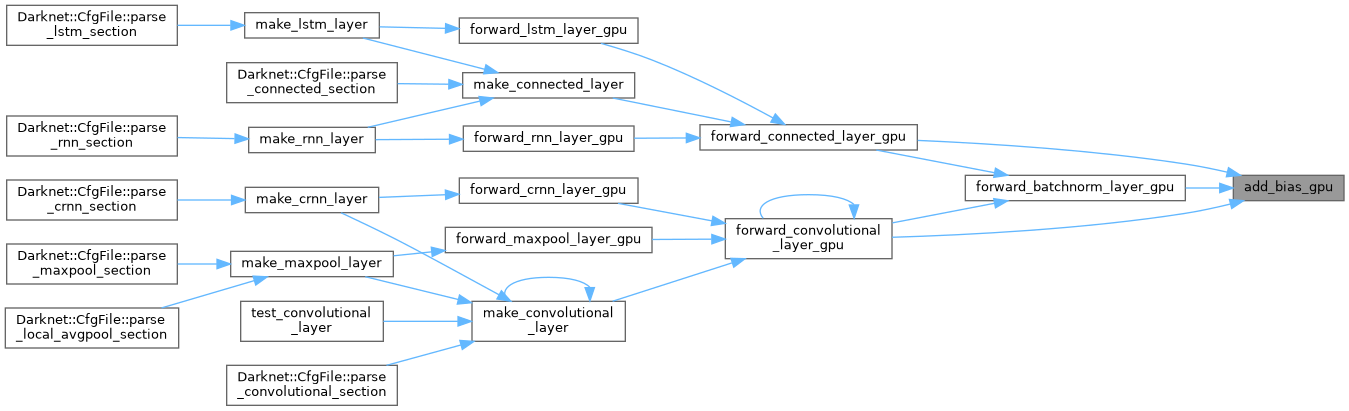
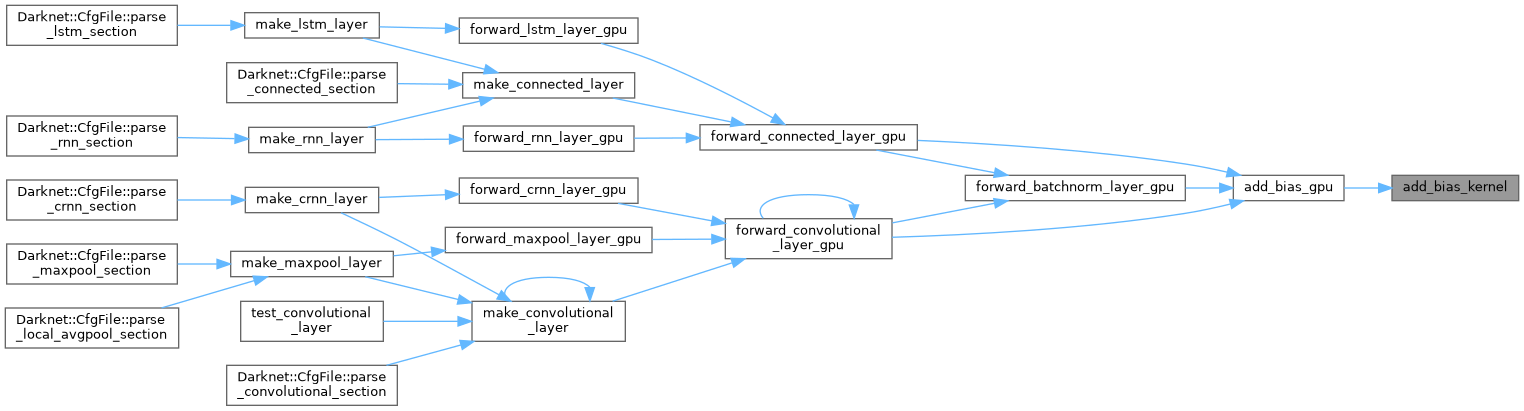
| void add_bias_gpu | ( | float * | output, |
| float * | biases, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial | ||
| ) |

| __global__ void add_bias_kernel | ( | float * | output, |
| float * | biases, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| int | current_size | ||
| ) |
| __global__ void axpy_kernel | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | OFFX, | ||
| int | INCX, | ||
| float * | Y, | ||
| int | OFFY, | ||
| int | INCY | ||
| ) |
| void axpy_ongpu | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | INCX, | ||
| float * | Y, | ||
| int | INCY | ||
| ) |
| void axpy_ongpu_offset | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | OFFX, | ||
| int | INCX, | ||
| float * | Y, | ||
| int | OFFY, | ||
| int | INCY | ||
| ) |
| void backward_bias_gpu | ( | float * | bias_updates, |
| float * | delta, | ||
| int | batch, | ||
| int | n, | ||
| int | size | ||
| ) |

| __global__ void backward_bias_kernel | ( | float * | bias_updates, |
| float * | delta, | ||
| int | batch, | ||
| int | n, | ||
| int | size | ||
| ) |
| void backward_implicit_gpu | ( | int | batch, |
| int | nweights, | ||
| float * | weight_updates_gpu, | ||
| float * | delta_gpu | ||
| ) |
| __global__ void backward_implicit_kernel | ( | int | size, |
| int | batch, | ||
| int | nweights, | ||
| float * | weight_updates_gpu, | ||
| float * | delta_gpu | ||
| ) |

| void backward_sam_gpu | ( | float * | in_w_h_c_delta, |
| int | size, | ||
| int | channel_size, | ||
| float * | in_scales_c, | ||
| float * | out_from_delta, | ||
| float * | in_from_output, | ||
| float * | out_state_delta | ||
| ) |
| __global__ void backward_sam_kernel | ( | float * | in_w_h_c_delta, |
| int | size, | ||
| int | channel_size, | ||
| float * | in_scales_c, | ||
| float * | out_from_delta, | ||
| float * | in_from_output, | ||
| float * | out_state_delta | ||
| ) |

| void backward_scale_channels_gpu | ( | float * | in_w_h_c_delta, |
| int | size, | ||
| int | channel_size, | ||
| int | batch_size, | ||
| int | scale_wh, | ||
| float * | in_scales_c, | ||
| float * | out_from_delta, | ||
| float * | in_from_output, | ||
| float * | out_state_delta | ||
| ) |
| __global__ void backward_scale_channels_kernel | ( | float * | in_w_h_c_delta, |
| int | size, | ||
| int | channel_size, | ||
| int | batch_size, | ||
| int | scale_wh, | ||
| float * | in_scales_c, | ||
| float * | out_from_delta, | ||
| float * | in_from_output, | ||
| float * | out_state_delta | ||
| ) |


| void backward_scale_gpu | ( | float * | x_norm, |
| float * | delta, | ||
| int | batch, | ||
| int | n, | ||
| int | size, | ||
| float * | scale_updates | ||
| ) |

| __global__ void backward_scale_kernel | ( | float * | x_norm, |
| float * | delta, | ||
| int | batch, | ||
| int | n, | ||
| int | size, | ||
| float * | scale_updates | ||
| ) |
| void backward_shortcut_multilayer_gpu | ( | int | src_outputs, |
| int | batch, | ||
| int | n, | ||
| int * | outputs_of_layers_gpu, | ||
| float ** | layers_delta_gpu, | ||
| float * | delta_out, | ||
| float * | delta_in, | ||
| float * | weights_gpu, | ||
| float * | weight_updates_gpu, | ||
| int | nweights, | ||
| float * | in, | ||
| float ** | layers_output_gpu, | ||
| WEIGHTS_NORMALIZATION_T | weights_normalization | ||
| ) |
| __global__ void backward_shortcut_multilayer_kernel | ( | int | size, |
| int | src_outputs, | ||
| int | batch, | ||
| int | n, | ||
| int * | outputs_of_layers_gpu, | ||
| float ** | layers_delta_gpu, | ||
| float * | delta_out, | ||
| float * | delta_in, | ||
| float * | weights_gpu, | ||
| float * | weight_updates_gpu, | ||
| int | nweights, | ||
| float * | in, | ||
| float ** | layers_output_gpu, | ||
| WEIGHTS_NORMALIZATION_T | weights_normalization | ||
| ) |

| __global__ void const_kernel | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | INCX | ||
| ) |

| void const_ongpu | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | INCX | ||
| ) |
| __global__ void constrain_kernel | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | INCX | ||
| ) |
| __global__ void constrain_min_max_kernel | ( | int | N, |
| float | MIN, | ||
| float | MAX, | ||
| float * | X, | ||
| int | INCX | ||
| ) |

| void constrain_min_max_ongpu | ( | int | N, |
| float | MIN, | ||
| float | MAX, | ||
| float * | X, | ||
| int | INCX | ||
| ) |

| void constrain_ongpu | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | INCX | ||
| ) |

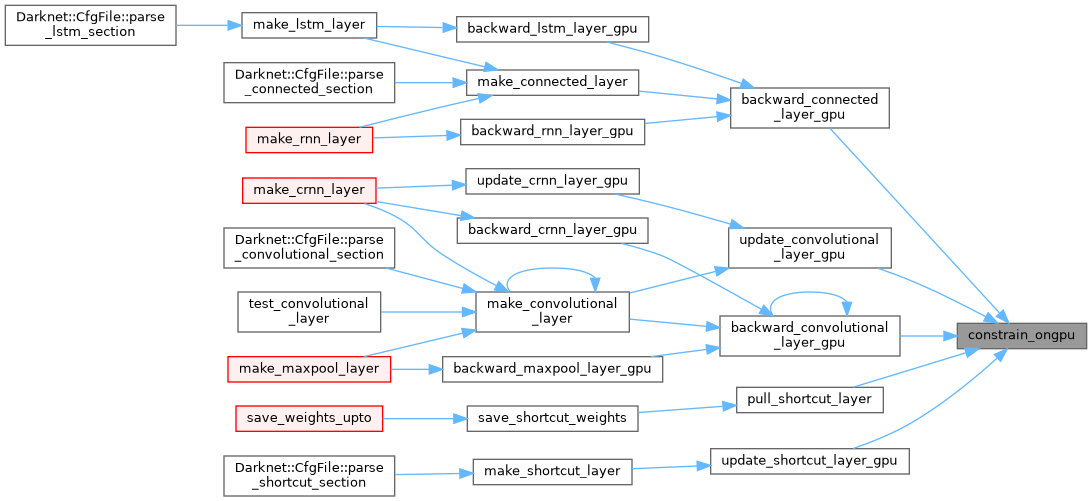
| __global__ void constrain_weight_updates_kernel | ( | int | N, |
| float | coef, | ||
| float * | weights_gpu, | ||
| float * | weight_updates_gpu | ||
| ) |

| void constrain_weight_updates_ongpu | ( | int | N, |
| float | coef, | ||
| float * | weights_gpu, | ||
| float * | weight_updates_gpu | ||
| ) |
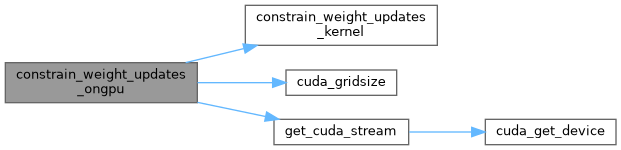
| void coord_conv_gpu | ( | float * | dst, |
| int | size, | ||
| int | w, | ||
| int | h, | ||
| int | chan, | ||
| int | b, | ||
| int | type | ||
| ) |

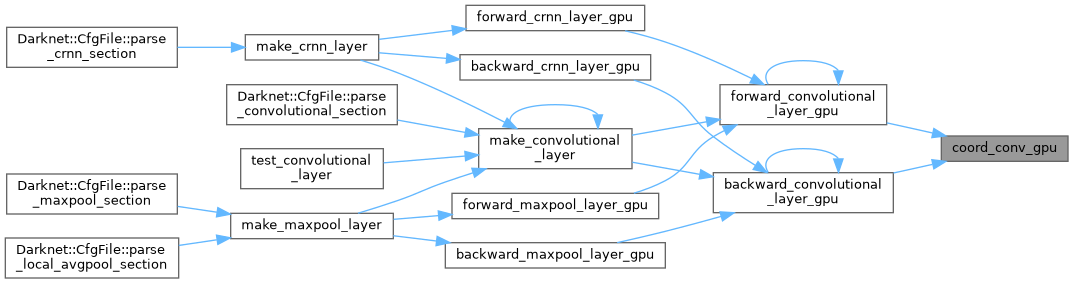
| __global__ void coord_conv_kernel | ( | float * | dst, |
| int | w, | ||
| int | h, | ||
| int | chan, | ||
| int | batch, | ||
| int | type | ||
| ) |
| __global__ void copy_kernel | ( | int | N, |
| float * | X, | ||
| int | OFFX, | ||
| int | INCX, | ||
| float * | Y, | ||
| int | OFFY, | ||
| int | INCY | ||
| ) |
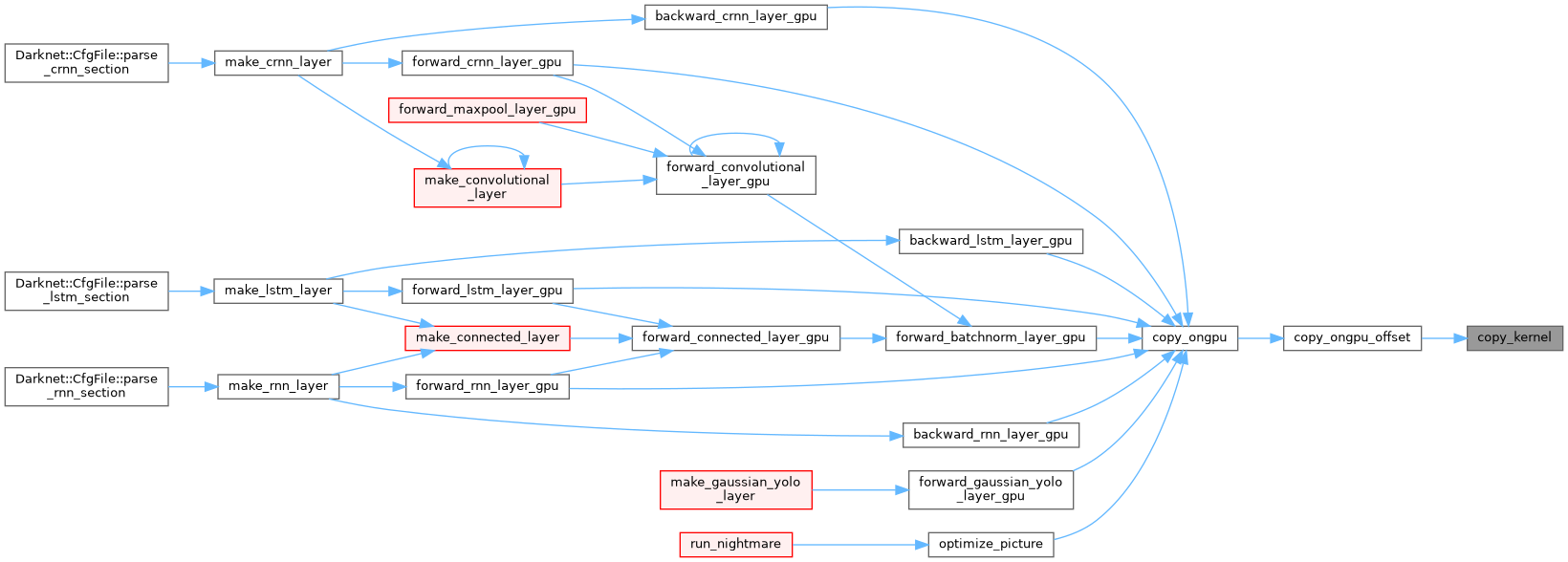
| void copy_ongpu | ( | int | N, |
| float * | X, | ||
| int | INCX, | ||
| float * | Y, | ||
| int | INCY | ||
| ) |
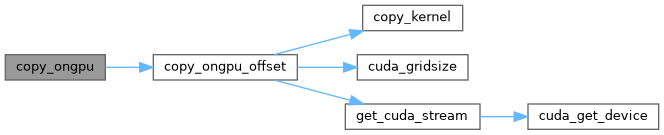
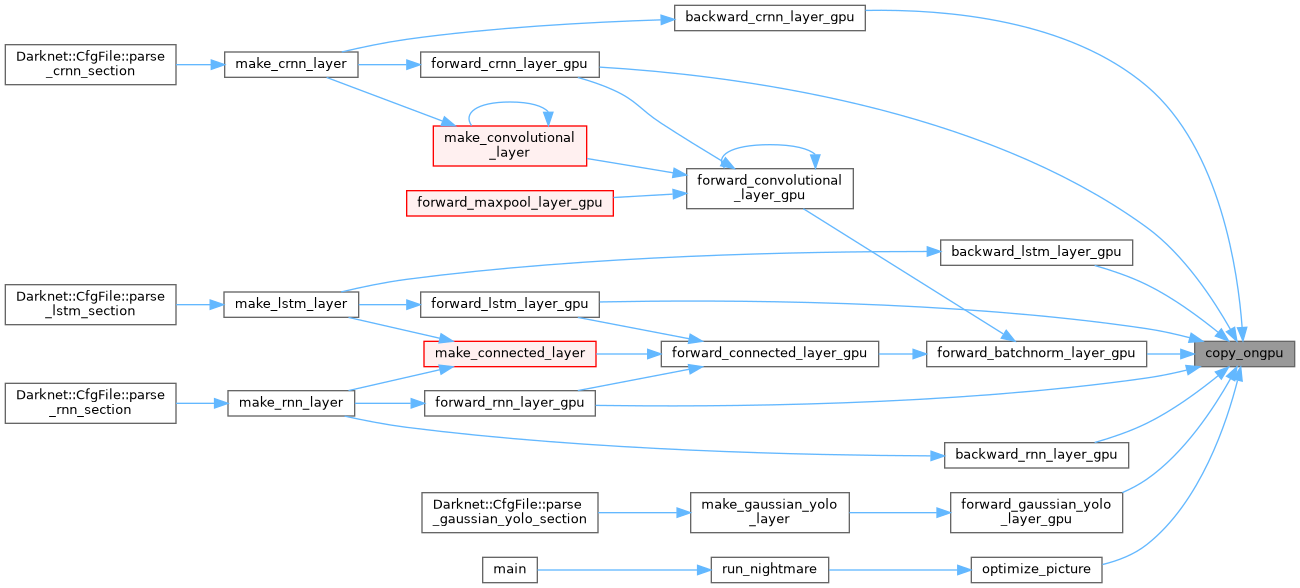
| void copy_ongpu_offset | ( | int | N, |
| float * | X, | ||
| int | OFFX, | ||
| int | INCX, | ||
| float * | Y, | ||
| int | OFFY, | ||
| int | INCY | ||
| ) |
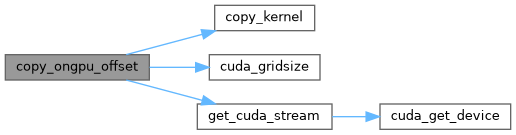
| void expand_array_gpu | ( | const float * | src_gpu, |
| float * | dst_gpu, | ||
| int | size, | ||
| int | groups | ||
| ) |
| __global__ void expand_array_kernel | ( | const float * | src_gpu, |
| float * | dst_gpu, | ||
| int | current_size, | ||
| int | groups | ||
| ) |

| void fast_mean_delta_gpu | ( | float * | delta, |
| float * | variance, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | mean_delta | ||
| ) |

| __global__ void fast_mean_delta_kernel | ( | float * | delta, |
| float * | variance, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | mean_delta | ||
| ) |
| void fast_mean_gpu | ( | float * | x, |
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | mean | ||
| ) |

| __global__ void fast_mean_kernel | ( | float * | x, |
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | mean | ||
| ) |
| void fast_v_cbn_gpu | ( | const float * | x, |
| float * | mean, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| int | minibatch_index, | ||
| int | max_minibatch_index, | ||
| float * | m_avg, | ||
| float * | v_avg, | ||
| float * | variance, | ||
| const float | alpha, | ||
| float * | rolling_mean_gpu, | ||
| float * | rolling_variance_gpu, | ||
| int | inverse_variance, | ||
| float | epsilon | ||
| ) |

| __global__ void fast_v_cbn_kernel | ( | const float * | x, |
| float * | mean, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| int | minibatch_index, | ||
| int | max_minibatch_index, | ||
| float * | m_avg, | ||
| float * | v_avg, | ||
| float * | variance, | ||
| const float | alpha, | ||
| float * | rolling_mean_gpu, | ||
| float * | rolling_variance_gpu, | ||
| int | inverse_variance, | ||
| float | epsilon | ||
| ) |
| void fast_variance_delta_gpu | ( | float * | x, |
| float * | delta, | ||
| float * | mean, | ||
| float * | variance, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | variance_delta | ||
| ) |

| __global__ void fast_variance_delta_kernel | ( | float * | x, |
| float * | delta, | ||
| float * | mean, | ||
| float * | variance, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | variance_delta | ||
| ) |
| void fast_variance_gpu | ( | float * | x, |
| float * | mean, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | variance | ||
| ) |

| __global__ void fast_variance_kernel | ( | float * | x, |
| float * | mean, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | variance | ||
| ) |
| __global__ void fill_kernel | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | INCX | ||
| ) |
| void fill_ongpu | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | INCX | ||
| ) |
| void fix_nan_and_inf | ( | float * | input, |
| size_t | size | ||
| ) |

| __global__ void fix_nan_and_inf_kernel | ( | float * | input, |
| size_t | size | ||
| ) |
| __global__ void flatten_kernel | ( | int | N, |
| float * | x, | ||
| int | spatial, | ||
| int | layers, | ||
| int | batch, | ||
| int | forward, | ||
| float * | out | ||
| ) |

| void flatten_ongpu | ( | float * | x, |
| int | spatial, | ||
| int | layers, | ||
| int | batch, | ||
| int | forward, | ||
| float * | out | ||
| ) |
| void forward_implicit_gpu | ( | int | batch, |
| int | nweights, | ||
| float * | weight_gpu, | ||
| float * | output_gpu | ||
| ) |
| __global__ void forward_implicit_kernel | ( | int | size, |
| int | batch, | ||
| int | nweights, | ||
| float * | weight_gpu, | ||
| float * | output_gpu | ||
| ) |

| __device__ float grad_lrelu | ( | float | src | ) |
| __device__ float grad_relu | ( | float | src | ) |
| void gradient_centralization_gpu | ( | int | w, |
| int | h, | ||
| int | c, | ||
| int | f, | ||
| float * | in | ||
| ) |

| __global__ void gradient_centralization_kernel | ( | int | filters, |
| int | f_size, | ||
| float * | in | ||
| ) |


| void input_shortcut_gpu | ( | float * | in, |
| int | batch, | ||
| int | w1, | ||
| int | h1, | ||
| int | c1, | ||
| float * | add, | ||
| int | w2, | ||
| int | h2, | ||
| int | c2, | ||
| float * | out | ||
| ) |
| __global__ void input_shortcut_kernel | ( | float * | in, |
| int | size, | ||
| int | minw, | ||
| int | minh, | ||
| int | minc, | ||
| int | stride, | ||
| int | sample, | ||
| int | batch, | ||
| int | w1, | ||
| int | h1, | ||
| int | c1, | ||
| float * | add, | ||
| int | w2, | ||
| int | h2, | ||
| int | c2, | ||
| float * | out | ||
| ) |

| __global__ void inverse_variance_kernel | ( | int | size, |
| float * | src, | ||
| float * | dst, | ||
| float | epsilon | ||
| ) |
| void inverse_variance_ongpu | ( | int | size, |
| float * | src, | ||
| float * | dst, | ||
| float | epsilon | ||
| ) |

| int is_nan_or_inf | ( | float * | input, |
| size_t | size | ||
| ) |

| __global__ void is_nan_or_inf_kernel | ( | float * | input, |
| size_t | size, | ||
| int * | pinned_return | ||
| ) |

| void l2_gpu | ( | int | n, |
| float * | pred, | ||
| float * | truth, | ||
| float * | delta, | ||
| float * | error | ||
| ) |
| __global__ void l2_kernel | ( | int | n, |
| float * | pred, | ||
| float * | truth, | ||
| float * | delta, | ||
| float * | error | ||
| ) |

| __device__ float lrelu | ( | float | src | ) |
| void mask_gpu_new_api | ( | int | N, |
| float * | X, | ||
| float | mask_num, | ||
| float * | mask, | ||
| float | val | ||
| ) |
| __global__ void mask_kernel | ( | int | n, |
| float * | x, | ||
| float | mask_num, | ||
| float * | mask | ||
| ) |

| __global__ void mask_kernel_new_api | ( | int | n, |
| float * | x, | ||
| float | mask_num, | ||
| float * | mask, | ||
| float | val | ||
| ) |

| void mask_ongpu | ( | int | N, |
| float * | X, | ||
| float | mask_num, | ||
| float * | mask | ||
| ) |
| void mean_array_gpu | ( | float * | src, |
| int | size, | ||
| float | alpha, | ||
| float * | avg | ||
| ) |

| __global__ void mean_array_kernel | ( | float * | src, |
| int | size, | ||
| float | alpha, | ||
| float * | avg | ||
| ) |
| void mean_delta_gpu | ( | float * | delta, |
| float * | variance, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | mean_delta | ||
| ) |
| __global__ void mean_delta_kernel | ( | float * | delta, |
| float * | variance, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | mean_delta | ||
| ) |

| void mean_gpu | ( | float * | x, |
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | mean | ||
| ) |
| __global__ void mean_kernel | ( | float * | x, |
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | mean | ||
| ) |

| void memcpy_ongpu | ( | void * | dst, |
| void * | src, | ||
| int | size_bytes | ||
| ) |

| __global__ void mul_kernel | ( | int | N, |
| float * | X, | ||
| int | INCX, | ||
| float * | Y, | ||
| int | INCY | ||
| ) |

| void mul_ongpu | ( | int | N, |
| float * | X, | ||
| int | INCX, | ||
| float * | Y, | ||
| int | INCY | ||
| ) |

| void mult_add_into_gpu | ( | int | num, |
| float * | a, | ||
| float * | b, | ||
| float * | c | ||
| ) |
| __global__ void mult_add_into_kernel | ( | int | n, |
| float * | a, | ||
| float * | b, | ||
| float * | c | ||
| ) |

| void mult_inverse_array_gpu | ( | const float * | src_gpu, |
| float * | dst_gpu, | ||
| int | size, | ||
| float | eps, | ||
| float | divider, | ||
| float | clip, | ||
| float | abs_add | ||
| ) |
| __global__ void mult_inverse_array_kernel | ( | const float * | src_gpu, |
| float * | dst_gpu, | ||
| int | size, | ||
| const float | eps, | ||
| float | divider, | ||
| const float | clip, | ||
| const float | abs_add | ||
| ) |

| void normalize_delta_gpu | ( | float * | x, |
| float * | mean, | ||
| float * | variance, | ||
| float * | mean_delta, | ||
| float * | variance_delta, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | delta | ||
| ) |

| __global__ void normalize_delta_kernel | ( | int | N, |
| float * | x, | ||
| float * | mean, | ||
| float * | variance, | ||
| float * | mean_delta, | ||
| float * | variance_delta, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | delta | ||
| ) |
| void normalize_gpu | ( | float * | x, |
| float * | mean, | ||
| float * | variance, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial | ||
| ) |

| __global__ void normalize_kernel | ( | int | N, |
| float * | x, | ||
| float * | mean, | ||
| float * | variance, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial | ||
| ) |
| void normalize_scale_bias_gpu | ( | float * | x, |
| float * | mean, | ||
| float * | variance, | ||
| float * | scales, | ||
| float * | biases, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| int | inverse_variance, | ||
| float | epsilon | ||
| ) |

| __global__ void normalize_scale_bias_kernel | ( | int | N, |
| float * | x, | ||
| float * | mean, | ||
| float * | variance, | ||
| float * | scales, | ||
| float * | biases, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| int | inverse_variance, | ||
| float | epsilon | ||
| ) |
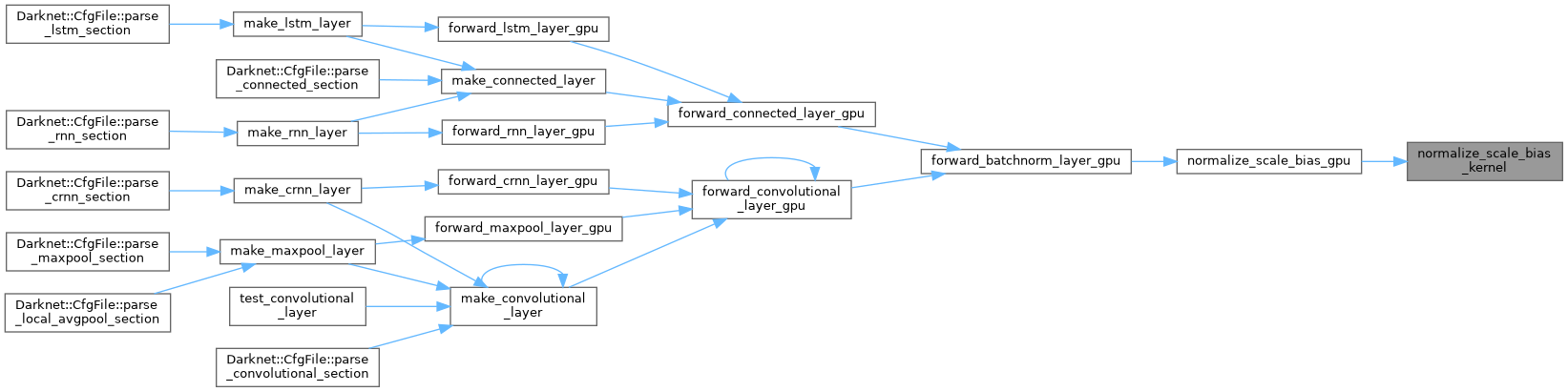
| void P_constrastive_f_det_gpu | ( | int * | labels, |
| unsigned int | feature_size, | ||
| float | temperature, | ||
| contrastive_params * | contrast_p, | ||
| const int | contrast_p_size | ||
| ) |


| __global__ void P_constrastive_f_det_kernel | ( | int * | labels, |
| unsigned int | feature_size, | ||
| float | temperature, | ||
| contrastive_params * | contrast_p, | ||
| const int | contrast_p_size | ||
| ) |

| __global__ void pow_kernel | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | INCX, | ||
| float * | Y, | ||
| int | INCY | ||
| ) |

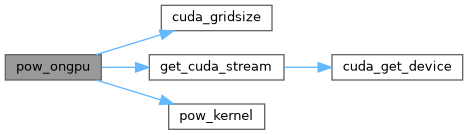
| void pow_ongpu | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | INCX, | ||
| float * | Y, | ||
| int | INCY | ||
| ) |
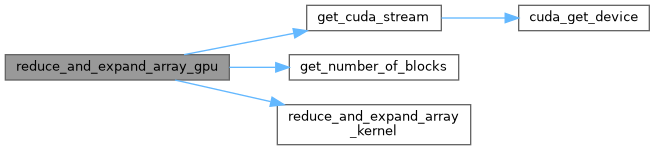
| void reduce_and_expand_array_gpu | ( | const float * | src_gpu, |
| float * | dst_gpu, | ||
| int | size, | ||
| int | groups | ||
| ) |
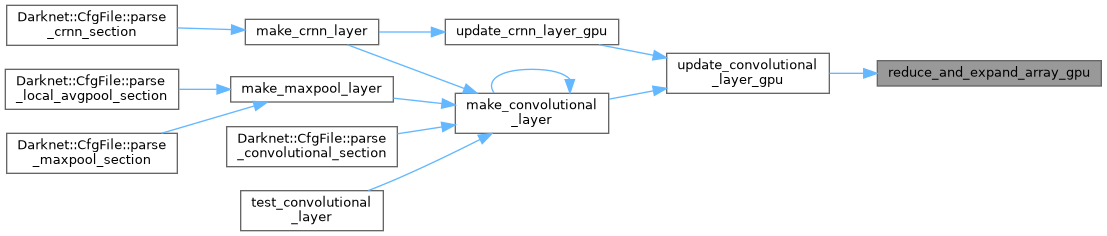
| __global__ void reduce_and_expand_array_kernel | ( | const float * | src_gpu, |
| float * | dst_gpu, | ||
| int | current_size, | ||
| int | groups | ||
| ) |

| __device__ float relu | ( | float | src | ) |
| __global__ void reorg_kernel | ( | int | N, |
| float * | x, | ||
| int | w, | ||
| int | h, | ||
| int | c, | ||
| int | batch, | ||
| int | stride, | ||
| int | forward, | ||
| float * | out | ||
| ) |

| void reorg_ongpu | ( | float * | x, |
| int | w, | ||
| int | h, | ||
| int | c, | ||
| int | batch, | ||
| int | stride, | ||
| int | forward, | ||
| float * | out | ||
| ) |
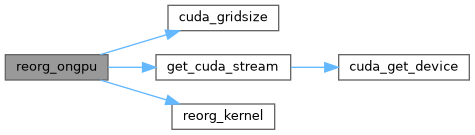
| void reset_nan_and_inf | ( | float * | input, |
| size_t | size | ||
| ) |

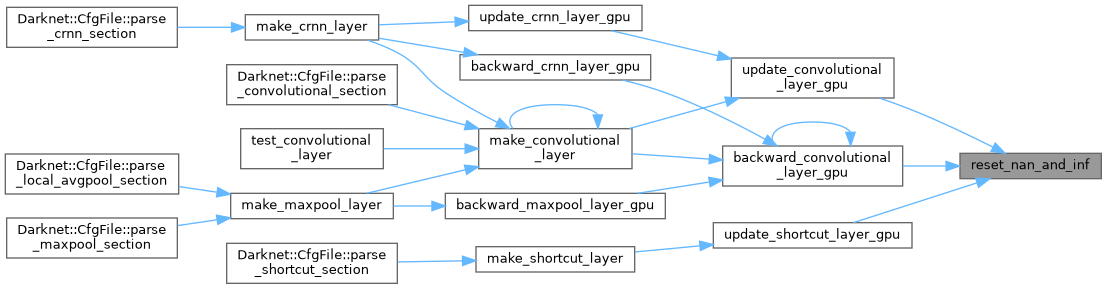
| __global__ void reset_nan_and_inf_kernel | ( | float * | input, |
| size_t | size | ||
| ) |
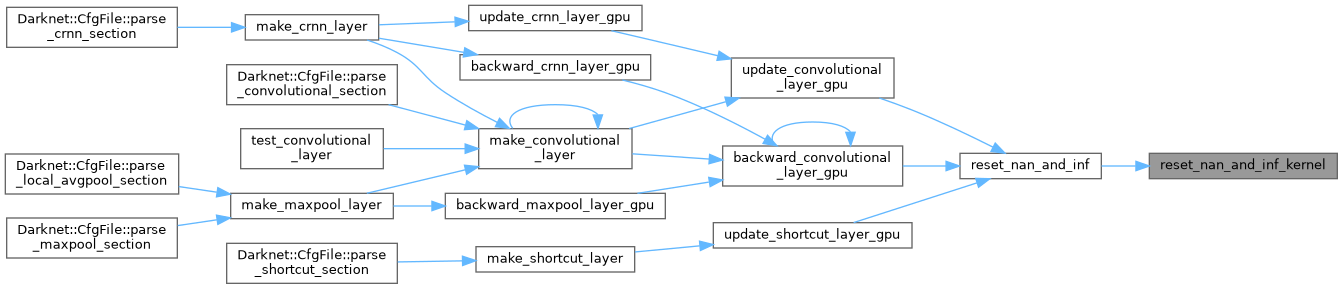
| void rotate_weights_gpu | ( | const float * | src_weight_gpu, |
| float * | weight_deform_gpu, | ||
| int | nweights, | ||
| int | n, | ||
| int | size, | ||
| int | reverse | ||
| ) |

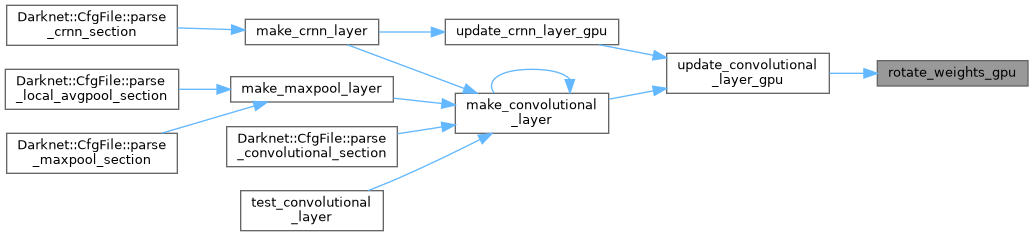
| __global__ void rotate_weights_kernel | ( | const float * | src_weight_gpu, |
| float * | weight_deform_gpu, | ||
| int | nweights, | ||
| int | n, | ||
| int | kernel_size, | ||
| int | reverse | ||
| ) |

| void sam_gpu | ( | float * | in_w_h_c, |
| int | size, | ||
| int | channel_size, | ||
| float * | scales_c, | ||
| float * | out | ||
| ) |
| __global__ void sam_kernel | ( | float * | in_w_h_c, |
| int | size, | ||
| int | channel_size, | ||
| float * | scales_c, | ||
| float * | out | ||
| ) |

| __global__ void scal_add_kernel | ( | int | N, |
| float | ALPHA, | ||
| float | BETA, | ||
| float * | X, | ||
| int | INCX | ||
| ) |

| void scal_add_ongpu | ( | int | N, |
| float | ALPHA, | ||
| float | BETA, | ||
| float * | X, | ||
| int | INCX | ||
| ) |

| __global__ void scal_kernel | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | INCX | ||
| ) |
| void scal_ongpu | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | INCX | ||
| ) |
| void scale_bias_gpu | ( | float * | output, |
| float * | scale, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial | ||
| ) |

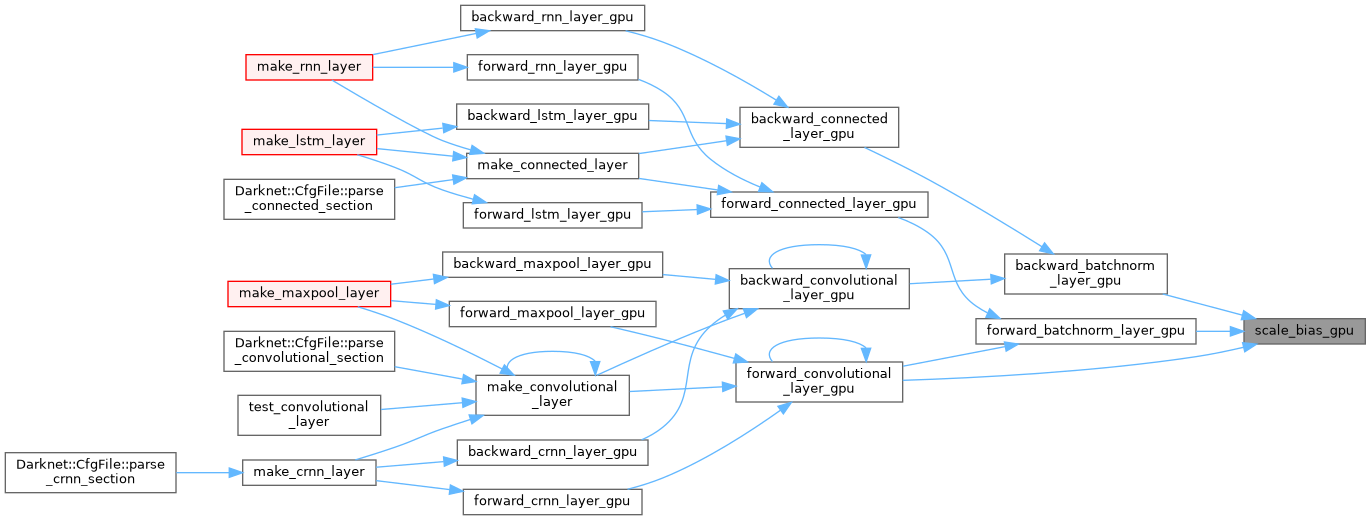
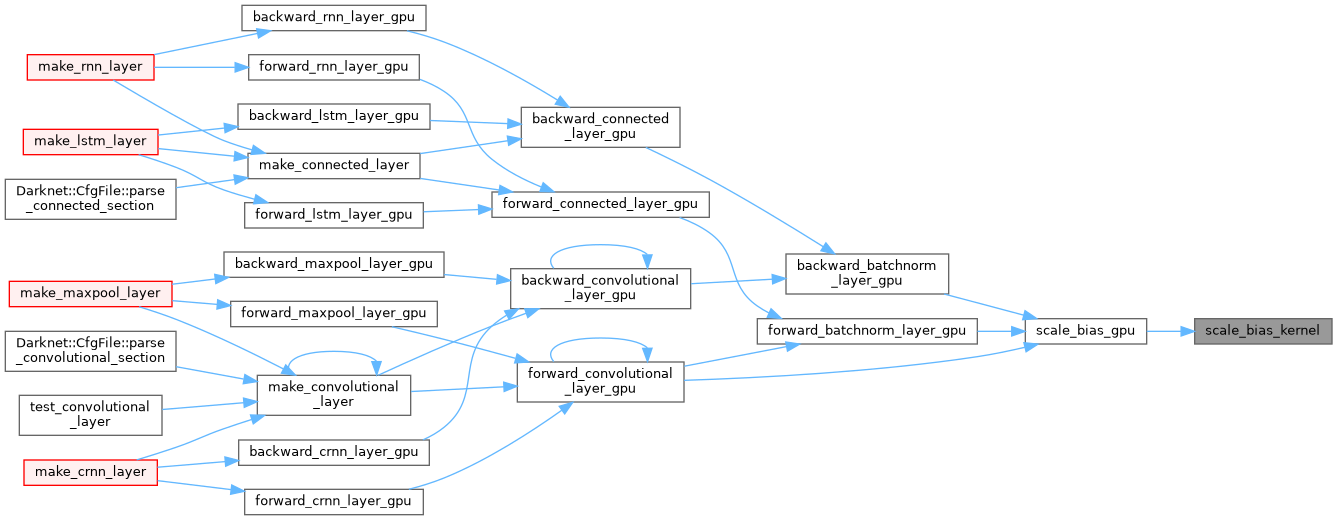
| __global__ void scale_bias_kernel | ( | float * | output, |
| float * | scale, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| int | current_size | ||
| ) |
| void scale_channels_gpu | ( | float * | in_w_h_c, |
| int | size, | ||
| int | channel_size, | ||
| int | batch_size, | ||
| int | scale_wh, | ||
| float * | scales_c, | ||
| float * | out | ||
| ) |

| __global__ void scale_channels_kernel | ( | float * | in_w_h_c, |
| int | size, | ||
| int | channel_size, | ||
| int | batch_size, | ||
| int | scale_wh, | ||
| float * | scales_c, | ||
| float * | out | ||
| ) |

| void shortcut_gpu | ( | int | batch, |
| int | w1, | ||
| int | h1, | ||
| int | c1, | ||
| float * | add, | ||
| int | w2, | ||
| int | h2, | ||
| int | c2, | ||
| float * | out | ||
| ) |
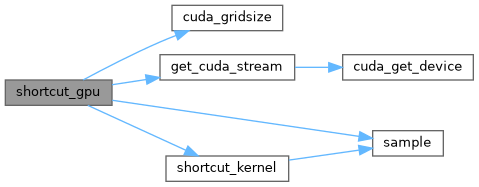
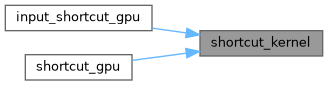
| __global__ void shortcut_kernel | ( | int | size, |
| int | minw, | ||
| int | minh, | ||
| int | minc, | ||
| int | stride, | ||
| int | sample, | ||
| int | batch, | ||
| int | w1, | ||
| int | h1, | ||
| int | c1, | ||
| float * | add, | ||
| int | w2, | ||
| int | h2, | ||
| int | c2, | ||
| float * | out | ||
| ) |

| void shortcut_multilayer_gpu | ( | int | src_outputs, |
| int | batch, | ||
| int | n, | ||
| int * | outputs_of_layers_gpu, | ||
| float ** | layers_output_gpu, | ||
| float * | out, | ||
| float * | in, | ||
| float * | weights_gpu, | ||
| int | nweights, | ||
| WEIGHTS_NORMALIZATION_T | weights_normalization | ||
| ) |
| __global__ void shortcut_multilayer_kernel | ( | int | size, |
| int | src_outputs, | ||
| int | batch, | ||
| int | n, | ||
| int * | outputs_of_layers_gpu, | ||
| float ** | layers_output_gpu, | ||
| float * | out, | ||
| float * | in, | ||
| float * | weights_gpu, | ||
| int | nweights, | ||
| WEIGHTS_NORMALIZATION_T | weights_normalization | ||
| ) |


| __global__ void shortcut_singlelayer_simple_kernel | ( | int | size, |
| int | src_outputs, | ||
| int | batch, | ||
| int | n, | ||
| int * | outputs_of_layers_gpu, | ||
| float ** | layers_output_gpu, | ||
| float * | out, | ||
| float * | in, | ||
| float * | weights_gpu, | ||
| int | nweights, | ||
| WEIGHTS_NORMALIZATION_T | weights_normalization | ||
| ) |

| __global__ void simple_copy_kernel | ( | int | size, |
| float * | src, | ||
| float * | dst | ||
| ) |
| void simple_copy_ongpu | ( | int | size, |
| float * | src, | ||
| float * | dst | ||
| ) |

| __global__ void simple_input_shortcut_kernel | ( | float * | in, |
| int | size, | ||
| float * | add, | ||
| float * | out | ||
| ) |

| void smooth_l1_gpu | ( | int | n, |
| float * | pred, | ||
| float * | truth, | ||
| float * | delta, | ||
| float * | error | ||
| ) |

| __global__ void smooth_l1_kernel | ( | int | n, |
| float * | pred, | ||
| float * | truth, | ||
| float * | delta, | ||
| float * | error | ||
| ) |

| void smooth_rotate_weights_gpu | ( | const float * | src_weight_gpu, |
| float * | weight_deform_gpu, | ||
| int | nweights, | ||
| int | n, | ||
| int | size, | ||
| int | angle, | ||
| int | reverse | ||
| ) |

| __global__ void smooth_rotate_weights_kernel | ( | const float * | src_weight_gpu, |
| float * | weight_deform_gpu, | ||
| int | nweights, | ||
| int | n, | ||
| int | kernel_size, | ||
| int | angle, | ||
| int | reverse | ||
| ) |

| __device__ void softmax_device | ( | int | n, |
| float * | input, | ||
| float | temp, | ||
| float * | output | ||
| ) |

| __device__ void softmax_device_new_api | ( | float * | input, |
| int | n, | ||
| float | temp, | ||
| int | stride, | ||
| float * | output | ||
| ) |

| void softmax_gpu | ( | float * | input, |
| int | n, | ||
| int | offset, | ||
| int | groups, | ||
| float | temp, | ||
| float * | output | ||
| ) |
| void softmax_gpu_new_api | ( | float * | input, |
| int | n, | ||
| int | batch, | ||
| int | batch_offset, | ||
| int | groups, | ||
| int | group_offset, | ||
| int | stride, | ||
| float | temp, | ||
| float * | output | ||
| ) |
| __global__ void softmax_kernel | ( | int | n, |
| int | offset, | ||
| int | batch, | ||
| float * | input, | ||
| float | temp, | ||
| float * | output | ||
| ) |


| __global__ void softmax_kernel_new_api | ( | float * | input, |
| int | n, | ||
| int | batch, | ||
| int | batch_offset, | ||
| int | groups, | ||
| int | group_offset, | ||
| int | stride, | ||
| float | temp, | ||
| float * | output | ||
| ) |


| void softmax_tree_gpu | ( | float * | input, |
| int | spatial, | ||
| int | batch, | ||
| int | stride, | ||
| float | temp, | ||
| float * | output, | ||
| Darknet::Tree | hier | ||
| ) |
| __global__ void softmax_tree_kernel | ( | float * | input, |
| int | spatial, | ||
| int | batch, | ||
| int | stride, | ||
| float | temp, | ||
| float * | output, | ||
| int | groups, | ||
| int * | group_size, | ||
| int * | group_offset | ||
| ) |


| void softmax_x_ent_gpu | ( | int | n, |
| float * | pred, | ||
| float * | truth, | ||
| float * | delta, | ||
| float * | error | ||
| ) |
| __global__ void softmax_x_ent_kernel | ( | int | n, |
| float * | pred, | ||
| float * | truth, | ||
| float * | delta, | ||
| float * | error | ||
| ) |

| void stretch_sway_flip_weights_gpu | ( | const float * | src_weight_gpu, |
| float * | weight_deform_gpu, | ||
| int | nweights, | ||
| int | n, | ||
| int | size, | ||
| int | angle, | ||
| int | reverse | ||
| ) |
| __global__ void stretch_sway_flip_weights_kernel | ( | const float * | src_weight_gpu, |
| float * | weight_deform_gpu, | ||
| int | nweights, | ||
| int | n, | ||
| int | kernel_size, | ||
| float | angle, | ||
| int | reverse | ||
| ) |

| void stretch_weights_gpu | ( | const float * | src_weight_gpu, |
| float * | weight_deform_gpu, | ||
| int | nweights, | ||
| int | n, | ||
| int | size, | ||
| float | scale, | ||
| int | reverse | ||
| ) |
| __global__ void stretch_weights_kernel | ( | const float * | src_weight_gpu, |
| float * | weight_deform_gpu, | ||
| int | nweights, | ||
| int | n, | ||
| int | kernel_size, | ||
| float | scale, | ||
| int | reverse | ||
| ) |

| void sum_of_mults | ( | float * | a1, |
| float * | a2, | ||
| float * | b1, | ||
| float * | b2, | ||
| size_t | size, | ||
| float * | dst | ||
| ) |

| __global__ void sum_of_mults_kernel | ( | float * | a1, |
| float * | a2, | ||
| float * | b1, | ||
| float * | b2, | ||
| size_t | size, | ||
| float * | dst | ||
| ) |

| __global__ void supp_kernel | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | INCX | ||
| ) |

| void supp_ongpu | ( | int | N, |
| float | ALPHA, | ||
| float * | X, | ||
| int | INCX | ||
| ) |
| void sway_and_flip_weights_gpu | ( | const float * | src_weight_gpu, |
| float * | weight_deform_gpu, | ||
| int | nweights, | ||
| int | n, | ||
| int | size, | ||
| int | angle, | ||
| int | reverse | ||
| ) |

| __global__ void sway_and_flip_weights_kernel | ( | const float * | src_weight_gpu, |
| float * | weight_deform_gpu, | ||
| int | nweights, | ||
| int | n, | ||
| int | kernel_size, | ||
| int | angle, | ||
| int | reverse | ||
| ) |

| void upsample_gpu | ( | float * | in, |
| int | w, | ||
| int | h, | ||
| int | c, | ||
| int | batch, | ||
| int | stride, | ||
| int | forward, | ||
| float | scale, | ||
| float * | out | ||
| ) |
| __global__ void upsample_kernel | ( | size_t | N, |
| float * | x, | ||
| int | w, | ||
| int | h, | ||
| int | c, | ||
| int | batch, | ||
| int | stride, | ||
| int | forward, | ||
| float | scale, | ||
| float * | out | ||
| ) |

| __global__ void variance_delta_kernel | ( | float * | x, |
| float * | delta, | ||
| float * | mean, | ||
| float * | variance, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | variance_delta | ||
| ) |
| void variance_gpu | ( | float * | x, |
| float * | mean, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | variance | ||
| ) |
| __global__ void variance_kernel | ( | float * | x, |
| float * | mean, | ||
| int | batch, | ||
| int | filters, | ||
| int | spatial, | ||
| float * | variance | ||
| ) |

| __inline__ __device__ float warpAllReduceSum | ( | float | val | ) |
| void weighted_delta_gpu | ( | float * | a, |
| float * | b, | ||
| float * | s, | ||
| float * | da, | ||
| float * | db, | ||
| float * | ds, | ||
| int | num, | ||
| float * | dc | ||
| ) |
| __global__ void weighted_delta_kernel | ( | int | n, |
| float * | a, | ||
| float * | b, | ||
| float * | s, | ||
| float * | da, | ||
| float * | db, | ||
| float * | ds, | ||
| float * | dc | ||
| ) |

| void weighted_sum_gpu | ( | float * | a, |
| float * | b, | ||
| float * | s, | ||
| int | num, | ||
| float * | c | ||
| ) |
| __global__ void weighted_sum_kernel | ( | int | n, |
| float * | a, | ||
| float * | b, | ||
| float * | s, | ||
| float * | c | ||
| ) |
