|
Darknet/YOLO v5.0-41-g593bddc
Object Detection Framework
|

|
|
Darknet/YOLO v5.0-41-g593bddc
Object Detection Framework
|
|
Functions | |
| void | assisted_activation2_gpu (float alpha, float *output, float *gt_gpu, float *a_avg_gpu, int size, int channels, int batches) |
| __global__ void | assisted_activation2_kernel (float alpha, float *output, float *gt_gpu, float *a_avg_gpu, int size, int channels, int batches) |
| void | assisted_activation_gpu (float alpha, float *output, float *gt_gpu, float *a_avg_gpu, int size, int channels, int batches) |
| __global__ void | assisted_activation_kernel (float alpha, float *output, float *gt_gpu, float *a_avg_gpu, int size, int channels, int batches) |
| void | assisted_excitation_forward_gpu (Darknet::Layer &l, Darknet::NetworkState state) |
| void | backward_convolutional_layer_gpu (Darknet::Layer &l, Darknet::NetworkState state) |
| void | binarize_gpu (float *x, int n, float *binary) |
| void | binarize_input_gpu (float *input, int n, int size, float *binary) |
| __global__ void | binarize_input_kernel (float *input, int n, int size, float *binary) |
| __global__ void | binarize_kernel (float *x, int n, float *binary) |
| void | binarize_weights_gpu (float *weights, int n, int size, float *binary) |
| __global__ void | binarize_weights_kernel (float *weights, int n, int size, float *binary) |
| __global__ void | binarize_weights_mean_kernel (float *weights, int n, int size, float *binary, float *mean_arr_gpu) |
| void | calc_avg_activation_gpu (float *src, float *dst, int size, int channels, int batches) |
| __global__ void | calc_avg_activation_kernel (float *src, float *dst, int size, int channels, int batches) |
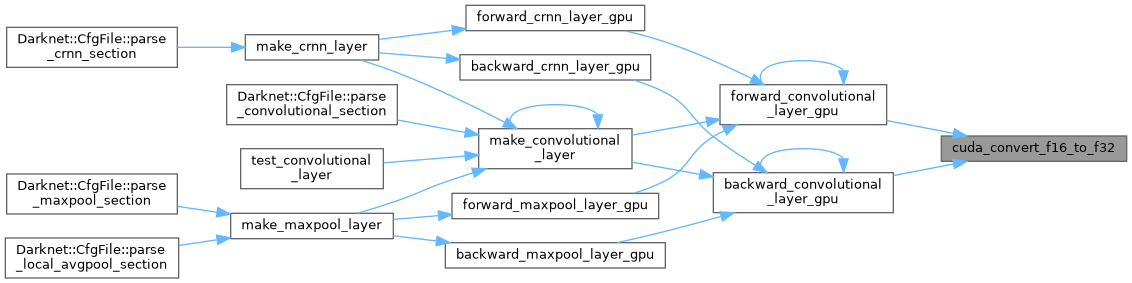
| void | cuda_convert_f16_to_f32 (float *input_f16, size_t size, float *output_f32) |
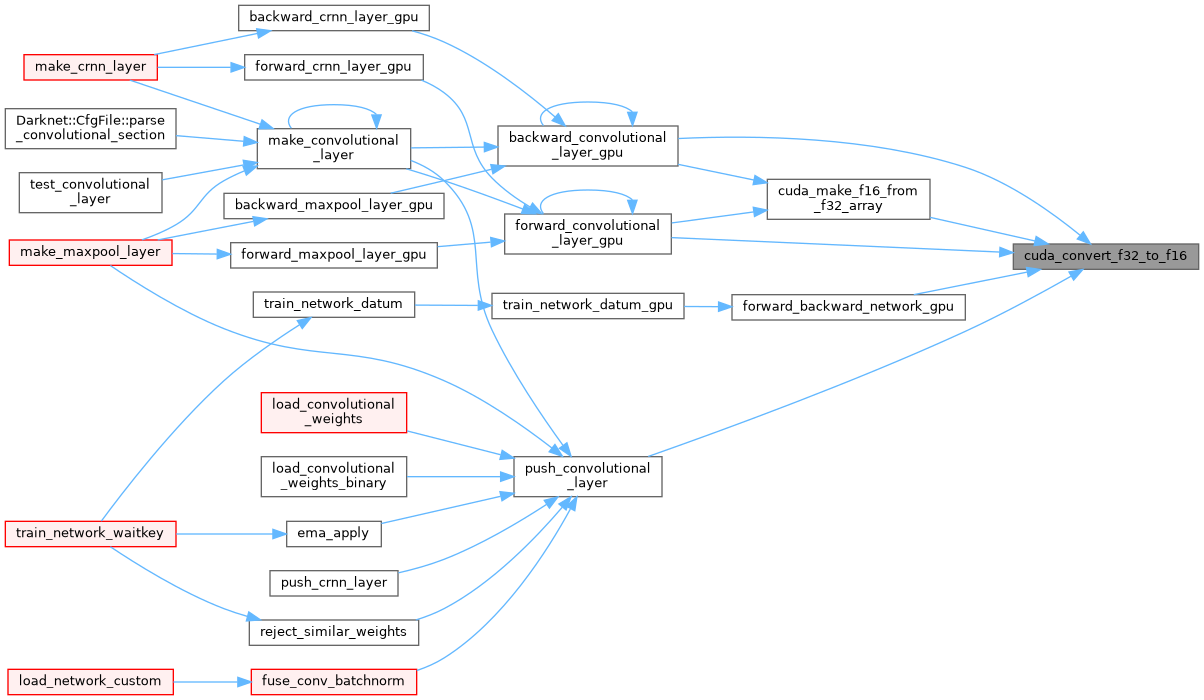
| void | cuda_convert_f32_to_f16 (float *input_f32, size_t size, float *output_f16) |
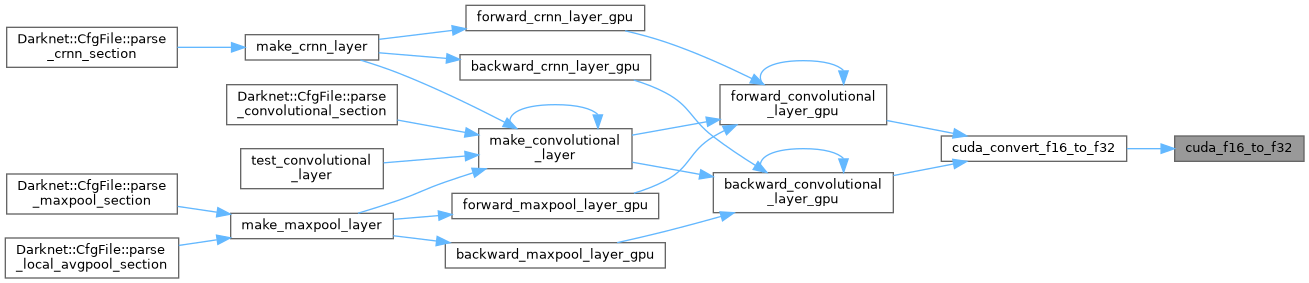
| __global__ void | cuda_f16_to_f32 (half *input_f16, size_t size, float *output_f32) |
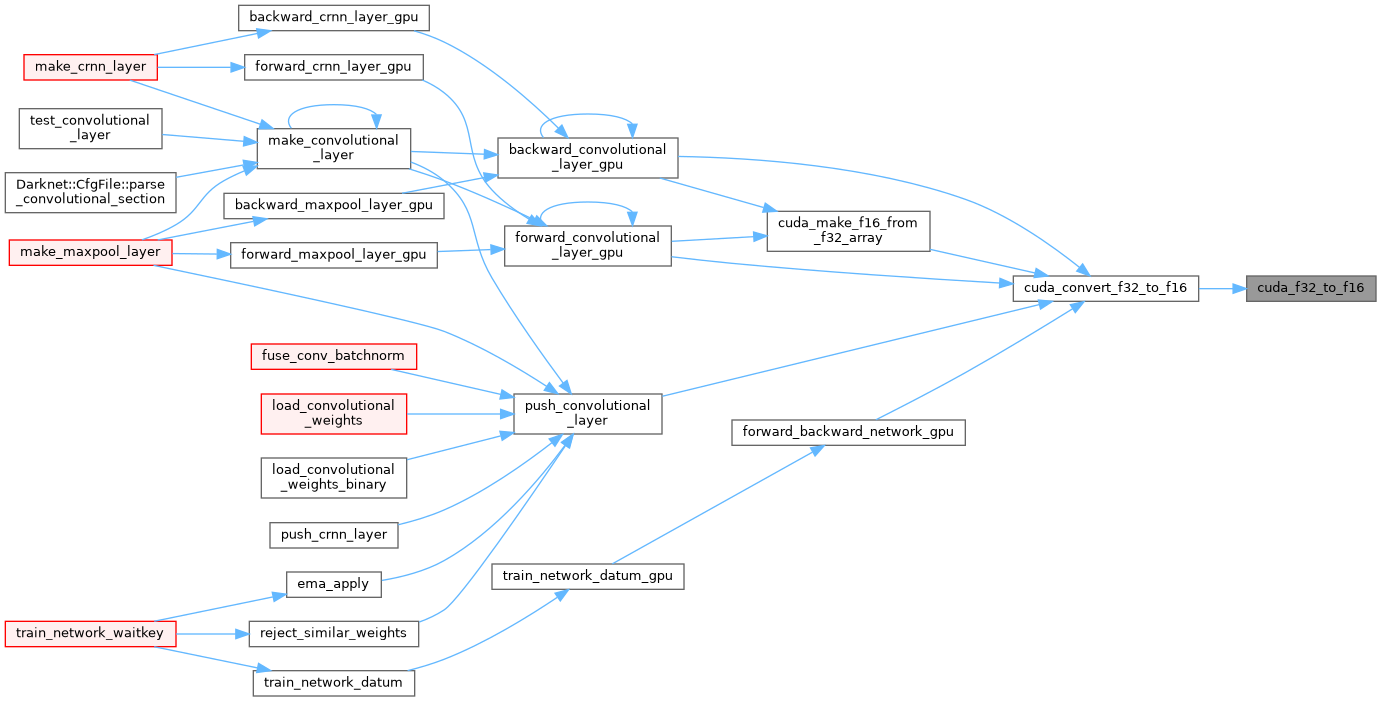
| __global__ void | cuda_f32_to_f16 (float *input_f32, size_t size, half *output_f16) |
| half * | cuda_make_f16_from_f32_array (float *src, size_t n) |
| void | fast_binarize_weights_gpu (float *weights, int n, int size, float *binary, float *mean_arr_gpu) |
| void | forward_convolutional_layer_gpu (Darknet::Layer &l, Darknet::NetworkState state) |
| void | pull_convolutional_layer (Darknet::Layer &l) |
| void | push_convolutional_layer (Darknet::Layer &l) |
| __global__ void | reduce_kernel (float *weights, int n, int size, float *mean_arr_gpu) |
| __global__ void | set_zero_kernel (float *src, int size) |
| void | update_convolutional_layer_gpu (Darknet::Layer &l, int batch, float learning_rate_init, float momentum, float decay, float loss_scale) |
| __inline__ __device__ float | warpAllReduceSum (float val) |
| void assisted_activation2_gpu | ( | float | alpha, |
| float * | output, | ||
| float * | gt_gpu, | ||
| float * | a_avg_gpu, | ||
| int | size, | ||
| int | channels, | ||
| int | batches | ||
| ) |
| __global__ void assisted_activation2_kernel | ( | float | alpha, |
| float * | output, | ||
| float * | gt_gpu, | ||
| float * | a_avg_gpu, | ||
| int | size, | ||
| int | channels, | ||
| int | batches | ||
| ) |

| void assisted_activation_gpu | ( | float | alpha, |
| float * | output, | ||
| float * | gt_gpu, | ||
| float * | a_avg_gpu, | ||
| int | size, | ||
| int | channels, | ||
| int | batches | ||
| ) |

| __global__ void assisted_activation_kernel | ( | float | alpha, |
| float * | output, | ||
| float * | gt_gpu, | ||
| float * | a_avg_gpu, | ||
| int | size, | ||
| int | channels, | ||
| int | batches | ||
| ) |

| void assisted_excitation_forward_gpu | ( | Darknet::Layer & | l, |
| Darknet::NetworkState | state | ||
| ) |
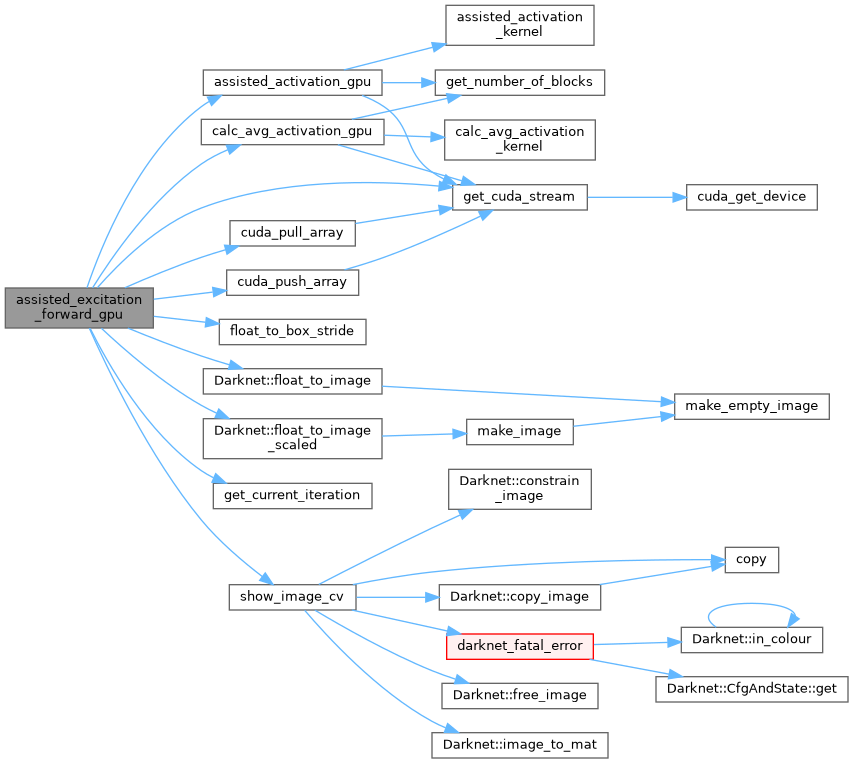
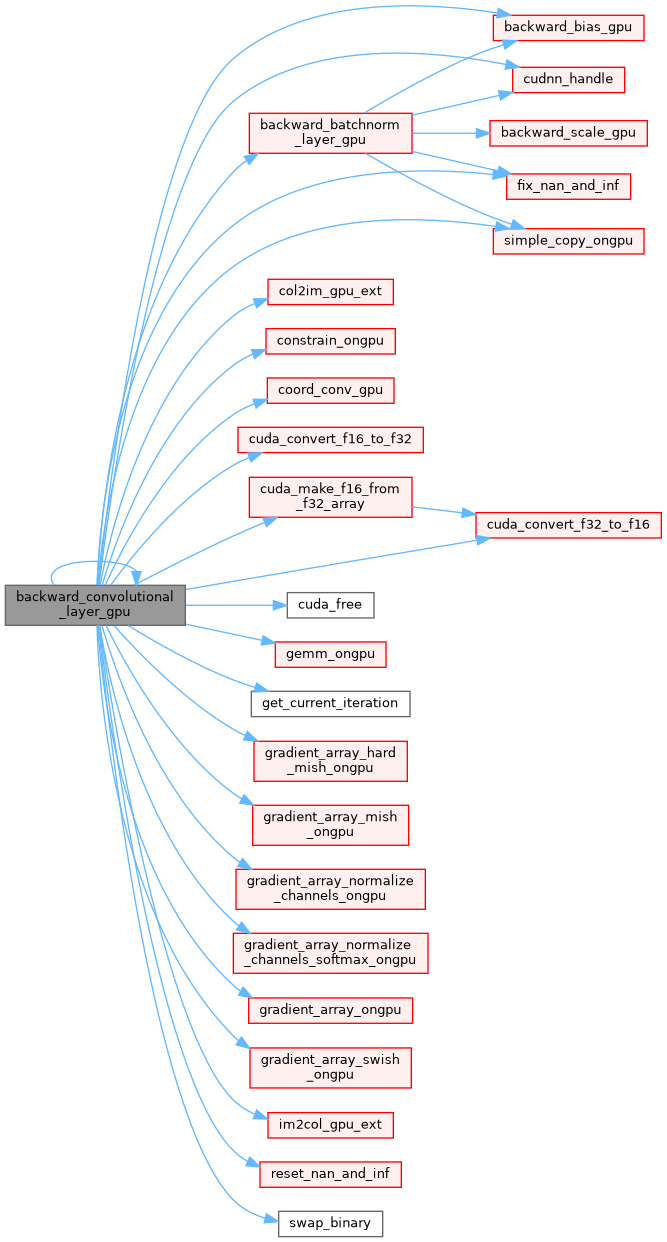
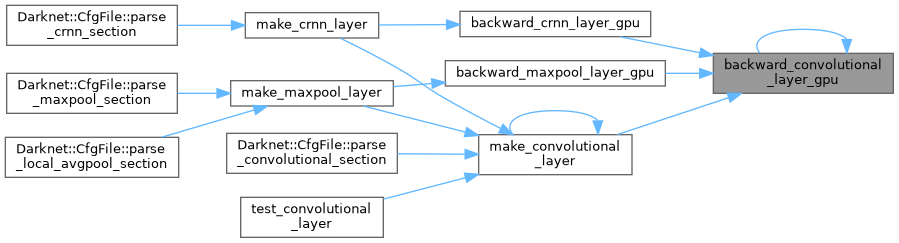
| void backward_convolutional_layer_gpu | ( | Darknet::Layer & | l, |
| Darknet::NetworkState | state | ||
| ) |
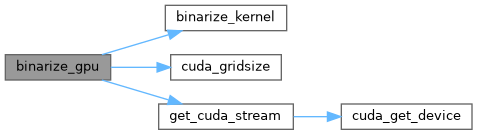
| void binarize_gpu | ( | float * | x, |
| int | n, | ||
| float * | binary | ||
| ) |
| void binarize_input_gpu | ( | float * | input, |
| int | n, | ||
| int | size, | ||
| float * | binary | ||
| ) |
| __global__ void binarize_input_kernel | ( | float * | input, |
| int | n, | ||
| int | size, | ||
| float * | binary | ||
| ) |

| __global__ void binarize_kernel | ( | float * | x, |
| int | n, | ||
| float * | binary | ||
| ) |
| void binarize_weights_gpu | ( | float * | weights, |
| int | n, | ||
| int | size, | ||
| float * | binary | ||
| ) |

| __global__ void binarize_weights_kernel | ( | float * | weights, |
| int | n, | ||
| int | size, | ||
| float * | binary | ||
| ) |

| __global__ void binarize_weights_mean_kernel | ( | float * | weights, |
| int | n, | ||
| int | size, | ||
| float * | binary, | ||
| float * | mean_arr_gpu | ||
| ) |

| void calc_avg_activation_gpu | ( | float * | src, |
| float * | dst, | ||
| int | size, | ||
| int | channels, | ||
| int | batches | ||
| ) |

| __global__ void calc_avg_activation_kernel | ( | float * | src, |
| float * | dst, | ||
| int | size, | ||
| int | channels, | ||
| int | batches | ||
| ) |

| void cuda_convert_f16_to_f32 | ( | float * | input_f16, |
| size_t | size, | ||
| float * | output_f32 | ||
| ) |

| void cuda_convert_f32_to_f16 | ( | float * | input_f32, |
| size_t | size, | ||
| float * | output_f16 | ||
| ) |

| __global__ void cuda_f16_to_f32 | ( | half * | input_f16, |
| size_t | size, | ||
| float * | output_f32 | ||
| ) |
| __global__ void cuda_f32_to_f16 | ( | float * | input_f32, |
| size_t | size, | ||
| half * | output_f16 | ||
| ) |
| half * cuda_make_f16_from_f32_array | ( | float * | src, |
| size_t | n | ||
| ) |
| void fast_binarize_weights_gpu | ( | float * | weights, |
| int | n, | ||
| int | size, | ||
| float * | binary, | ||
| float * | mean_arr_gpu | ||
| ) |
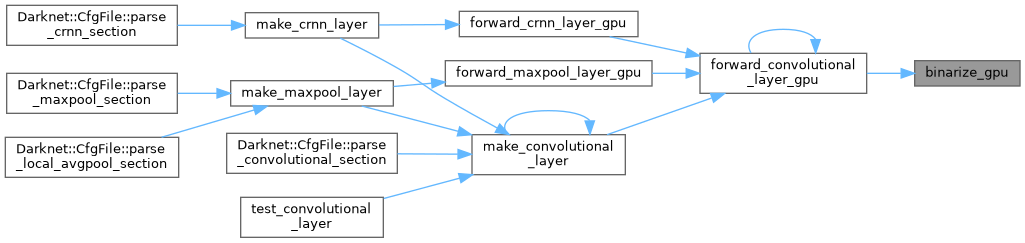
| void forward_convolutional_layer_gpu | ( | Darknet::Layer & | l, |
| Darknet::NetworkState | state | ||
| ) |
| void pull_convolutional_layer | ( | Darknet::Layer & | l | ) |

| void push_convolutional_layer | ( | Darknet::Layer & | l | ) |

| __global__ void reduce_kernel | ( | float * | weights, |
| int | n, | ||
| int | size, | ||
| float * | mean_arr_gpu | ||
| ) |


| __global__ void set_zero_kernel | ( | float * | src, |
| int | size | ||
| ) |

| void update_convolutional_layer_gpu | ( | Darknet::Layer & | l, |
| int | batch, | ||
| float | learning_rate_init, | ||
| float | momentum, | ||
| float | decay, | ||
| float | loss_scale | ||
| ) |
| __inline__ __device__ float warpAllReduceSum | ( | float | val | ) |
