|
Darknet/YOLO v5.0-41-g593bddc
Object Detection Framework
|

|
|
Darknet/YOLO v5.0-41-g593bddc
Object Detection Framework
|
|
General matrix multiplication (GEMM) More...
Macros | |
| #define | PUT_IN_REGISTER register |
| #define | swap(a0, a1, j, m) t = (a0 ^ (a1 >>j)) & m; a0 = a0 ^ t; a1 = a1 ^ (t << j); |
| #define | TILE_K 16 |
| #define | TILE_M 4 |
| #define | TILE_N 16 |
Functions | |
| void | activate_array_cpu_custom (float *x, const int n, const ACTIVATION a) |
| void | convolution_2d (int w, int h, int ksize, int n, int c, int pad, int stride, float *weights, float *input, float *output, float *mean) |
| void | convolution_repacked (uint32_t *packed_input, uint32_t *packed_weights, float *output, int w, int h, int c, int n, int size, int pad, int new_lda, float *mean_arr) |
| void | float_to_bit (float *src, unsigned char *dst, size_t size) |
| void | forward_maxpool_layer_avx (float *src, float *dst, int *indexes, int size, int w, int h, int out_w, int out_h, int c, int pad, int stride, int batch) |
| void | gemm_cpu (int TA, int TB, int M, int N, int K, float ALPHA, float *A, int lda, float *B, int ldb, float BETA, float *C, int ldc) |
| void | gemm_nn (int M, int N, int K, float ALPHA, float *A, int lda, float *B, int ldb, float *C, int ldc) |
| void | gemm_nn_bin_32bit_packed (int M, int N, int K, float ALPHA, uint32_t *A, int lda, uint32_t *B, int ldb, float *C, int ldc, float *mean_arr) |
| void | gemm_nn_bin_transposed_32bit_packed (int M, int N, int K, float ALPHA, uint32_t *A, int lda, uint32_t *B, int ldb, float *C, int ldc, float *mean_arr) |
| void | gemm_nn_custom_bin_mean_transposed (int M, int N, int K, float ALPHA_UNUSED, unsigned char *A, int lda, unsigned char *B, int ldb, float *C, int ldc, float *mean_arr) |
| void | gemm_nn_fast (int M, int N, int K, float ALPHA, float *A, int lda, float *B, int ldb, float *C, int ldc) |
| void | gemm_nt (int M, int N, int K, float ALPHA, float *A, int lda, float *B, int ldb, float *C, int ldc) |
| void | gemm_tn (int M, int N, int K, float ALPHA, float *A, int lda, float *B, int ldb, float *C, int ldc) |
| void | gemm_tt (int M, int N, int K, float ALPHA, float *A, int lda, float *B, int ldb, float *C, int ldc) |
| void | im2col_cpu_custom (float *data_im, int channels, int height, int width, int ksize, int stride, int pad, float *data_col) |
| void | im2col_cpu_custom_bin (float *data_im, int channels, int height, int width, int ksize, int stride, int pad, float *data_col, int bit_align) |
| void | im2col_cpu_custom_transpose (float *data_im, int channels, int height, int width, int ksize, int stride, int pad, float *data_col, int ldb_align) |
| void | init_cpu () |
| int | is_avx () |
| int | is_fma_avx2 () |
| float * | random_matrix (int rows, int cols) |
| void | repack_input (float *input, float *re_packed_input, int w, int h, int c) |
| uint32_t | reverse_32_bit (uint32_t a) |
| uint8_t | reverse_8_bit (uint8_t a) |
| unsigned char | reverse_byte (unsigned char a) |
| void | transpose32_optimized (uint32_t A[32]) |
| void | transpose8rS32_reversed_diagonale (unsigned char *A, unsigned char *B, int m, int n) |
| void | transpose_32x32_bits_reversed_diagonale (uint32_t *A, uint32_t *B, int m, int n) |
| void | transpose_bin (uint32_t *A, uint32_t *B, const int n, const int m, const int lda, const int ldb, const int block_size) |
| void | transpose_block_SSE4x4 (float *A, float *B, const int n, const int m, const int lda, const int ldb, const int block_size) |
| static void | transpose_scalar_block (float *A, float *B, const int lda, const int ldb, const int block_size) |
| void | transpose_uint32 (uint32_t *src, uint32_t *dst, int src_h, int src_w, int src_align, int dst_align) |
General matrix multiplication (GEMM)
| #define PUT_IN_REGISTER register |
| #define swap | ( | a0, | |
| a1, | |||
| j, | |||
| m | |||
| ) | t = (a0 ^ (a1 >>j)) & m; a0 = a0 ^ t; a1 = a1 ^ (t << j); |
| #define TILE_K 16 |
| #define TILE_M 4 |
| #define TILE_N 16 |
| void activate_array_cpu_custom | ( | float * | x, |
| const int | n, | ||
| const ACTIVATION | a | ||
| ) |
| void convolution_2d | ( | int | w, |
| int | h, | ||
| int | ksize, | ||
| int | n, | ||
| int | c, | ||
| int | pad, | ||
| int | stride, | ||
| float * | weights, | ||
| float * | input, | ||
| float * | output, | ||
| float * | mean | ||
| ) |
| void convolution_repacked | ( | uint32_t * | packed_input, |
| uint32_t * | packed_weights, | ||
| float * | output, | ||
| int | w, | ||
| int | h, | ||
| int | c, | ||
| int | n, | ||
| int | size, | ||
| int | pad, | ||
| int | new_lda, | ||
| float * | mean_arr | ||
| ) |
| void float_to_bit | ( | float * | src, |
| unsigned char * | dst, | ||
| size_t | size | ||
| ) |
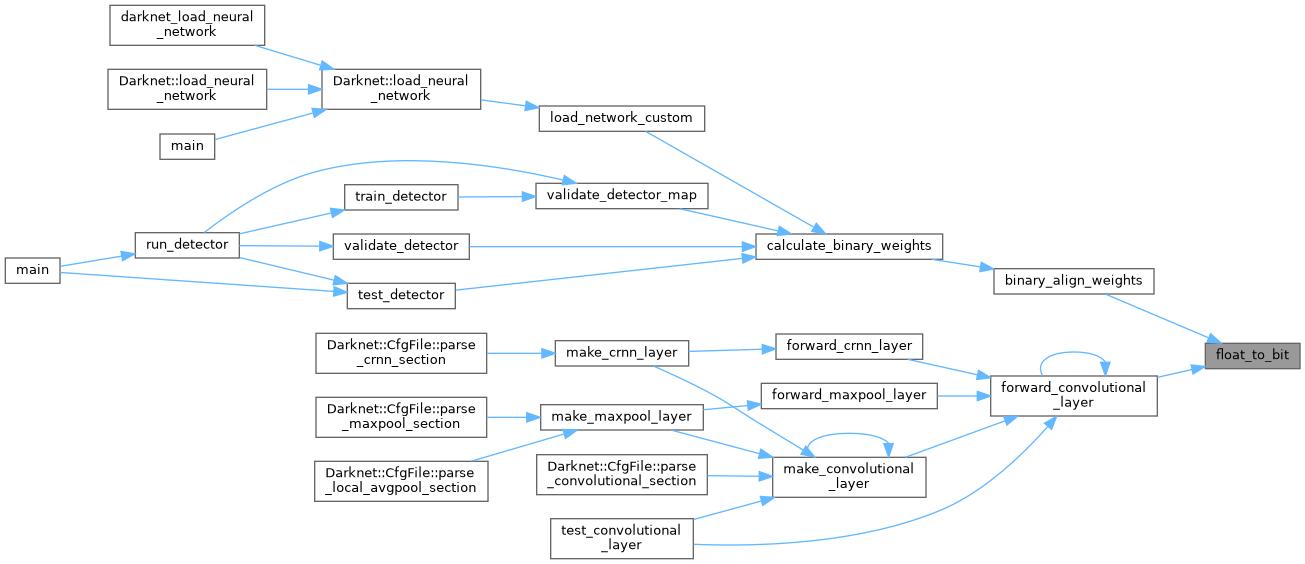
| void forward_maxpool_layer_avx | ( | float * | src, |
| float * | dst, | ||
| int * | indexes, | ||
| int | size, | ||
| int | w, | ||
| int | h, | ||
| int | out_w, | ||
| int | out_h, | ||
| int | c, | ||
| int | pad, | ||
| int | stride, | ||
| int | batch | ||
| ) |

| void gemm_cpu | ( | int | TA, |
| int | TB, | ||
| int | M, | ||
| int | N, | ||
| int | K, | ||
| float | ALPHA, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb, | ||
| float | BETA, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
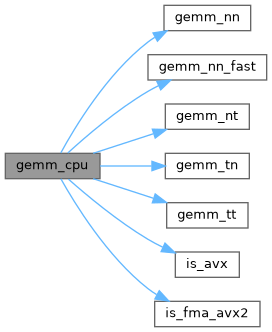
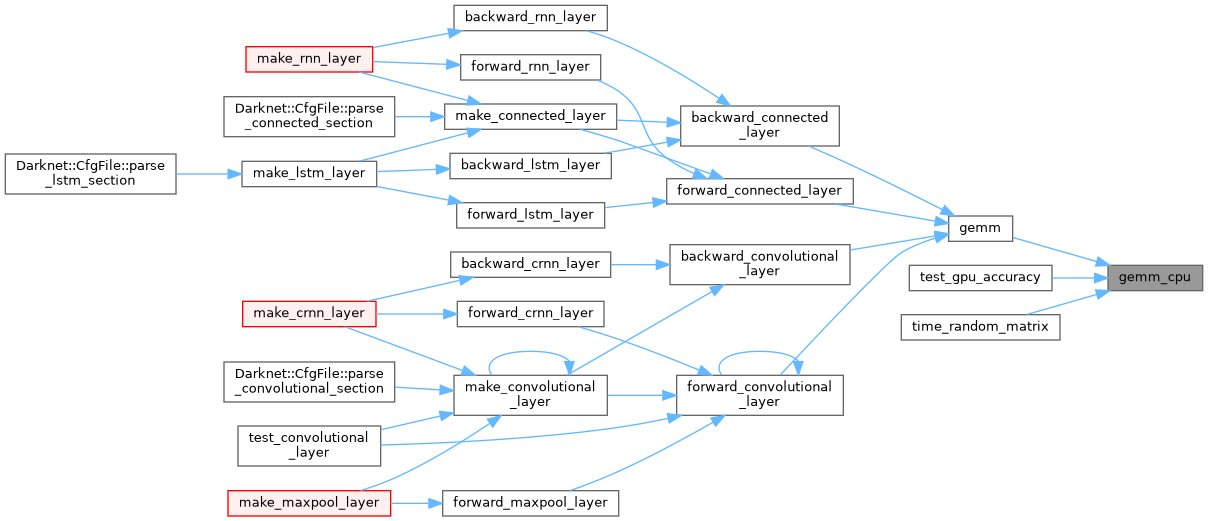
| void gemm_nn | ( | int | M, |
| int | N, | ||
| int | K, | ||
| float | ALPHA, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
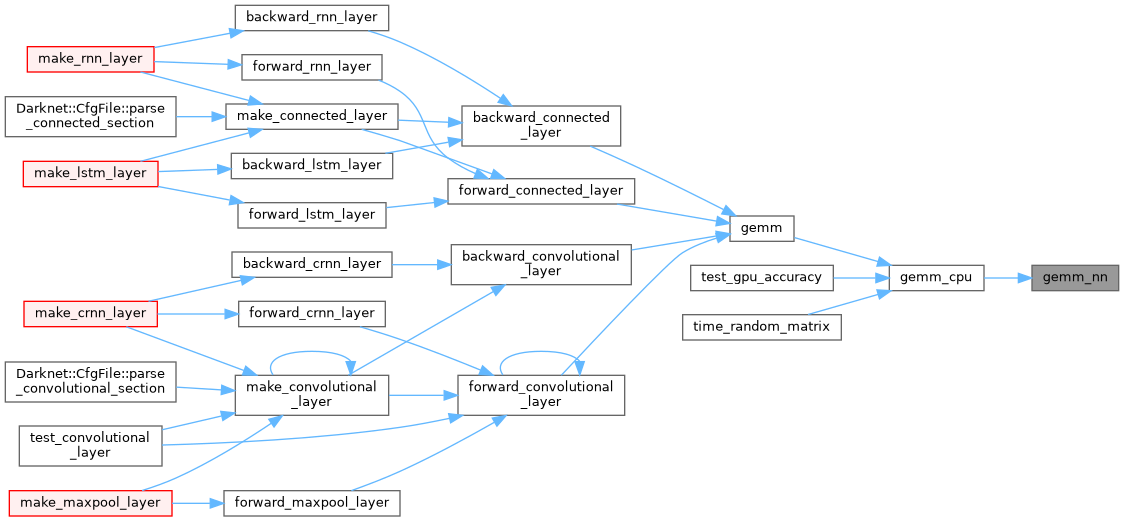
| void gemm_nn_bin_32bit_packed | ( | int | M, |
| int | N, | ||
| int | K, | ||
| float | ALPHA, | ||
| uint32_t * | A, | ||
| int | lda, | ||
| uint32_t * | B, | ||
| int | ldb, | ||
| float * | C, | ||
| int | ldc, | ||
| float * | mean_arr | ||
| ) |
| void gemm_nn_bin_transposed_32bit_packed | ( | int | M, |
| int | N, | ||
| int | K, | ||
| float | ALPHA, | ||
| uint32_t * | A, | ||
| int | lda, | ||
| uint32_t * | B, | ||
| int | ldb, | ||
| float * | C, | ||
| int | ldc, | ||
| float * | mean_arr | ||
| ) |
| void gemm_nn_custom_bin_mean_transposed | ( | int | M, |
| int | N, | ||
| int | K, | ||
| float | ALPHA_UNUSED, | ||
| unsigned char * | A, | ||
| int | lda, | ||
| unsigned char * | B, | ||
| int | ldb, | ||
| float * | C, | ||
| int | ldc, | ||
| float * | mean_arr | ||
| ) |
| void gemm_nn_fast | ( | int | M, |
| int | N, | ||
| int | K, | ||
| float | ALPHA, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
| void gemm_nt | ( | int | M, |
| int | N, | ||
| int | K, | ||
| float | ALPHA, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
| void gemm_tn | ( | int | M, |
| int | N, | ||
| int | K, | ||
| float | ALPHA, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
| void gemm_tt | ( | int | M, |
| int | N, | ||
| int | K, | ||
| float | ALPHA, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
| void im2col_cpu_custom | ( | float * | data_im, |
| int | channels, | ||
| int | height, | ||
| int | width, | ||
| int | ksize, | ||
| int | stride, | ||
| int | pad, | ||
| float * | data_col | ||
| ) |

| void im2col_cpu_custom_bin | ( | float * | data_im, |
| int | channels, | ||
| int | height, | ||
| int | width, | ||
| int | ksize, | ||
| int | stride, | ||
| int | pad, | ||
| float * | data_col, | ||
| int | bit_align | ||
| ) |
| void im2col_cpu_custom_transpose | ( | float * | data_im, |
| int | channels, | ||
| int | height, | ||
| int | width, | ||
| int | ksize, | ||
| int | stride, | ||
| int | pad, | ||
| float * | data_col, | ||
| int | ldb_align | ||
| ) |
| void init_cpu | ( | ) |
| int is_avx | ( | ) |
| int is_fma_avx2 | ( | ) |
| float * random_matrix | ( | int | rows, |
| int | cols | ||
| ) |
| void repack_input | ( | float * | input, |
| float * | re_packed_input, | ||
| int | w, | ||
| int | h, | ||
| int | c | ||
| ) |
| uint32_t reverse_32_bit | ( | uint32_t | a | ) |


| uint8_t reverse_8_bit | ( | uint8_t | a | ) |

| unsigned char reverse_byte | ( | unsigned char | a | ) |
| void transpose32_optimized | ( | uint32_t | A[32] | ) |


| void transpose8rS32_reversed_diagonale | ( | unsigned char * | A, |
| unsigned char * | B, | ||
| int | m, | ||
| int | n | ||
| ) |

| void transpose_32x32_bits_reversed_diagonale | ( | uint32_t * | A, |
| uint32_t * | B, | ||
| int | m, | ||
| int | n | ||
| ) |


| void transpose_bin | ( | uint32_t * | A, |
| uint32_t * | B, | ||
| const int | n, | ||
| const int | m, | ||
| const int | lda, | ||
| const int | ldb, | ||
| const int | block_size | ||
| ) |
| void transpose_block_SSE4x4 | ( | float * | A, |
| float * | B, | ||
| const int | n, | ||
| const int | m, | ||
| const int | lda, | ||
| const int | ldb, | ||
| const int | block_size | ||
| ) |
|
inlinestatic |
| void transpose_uint32 | ( | uint32_t * | src, |
| uint32_t * | dst, | ||
| int | src_h, | ||
| int | src_w, | ||
| int | src_align, | ||
| int | dst_align | ||
| ) |