|
Darknet/YOLO v5.0-41-g593bddc
Object Detection Framework
|

|
|
Darknet/YOLO v5.0-41-g593bddc
Object Detection Framework
|
|


Macros | |
| #define | USET |
Functions | |
| void | backward_rnn_layer (Darknet::Layer &l, Darknet::NetworkState state) |
| void | forward_rnn_layer (Darknet::Layer &l, Darknet::NetworkState state) |
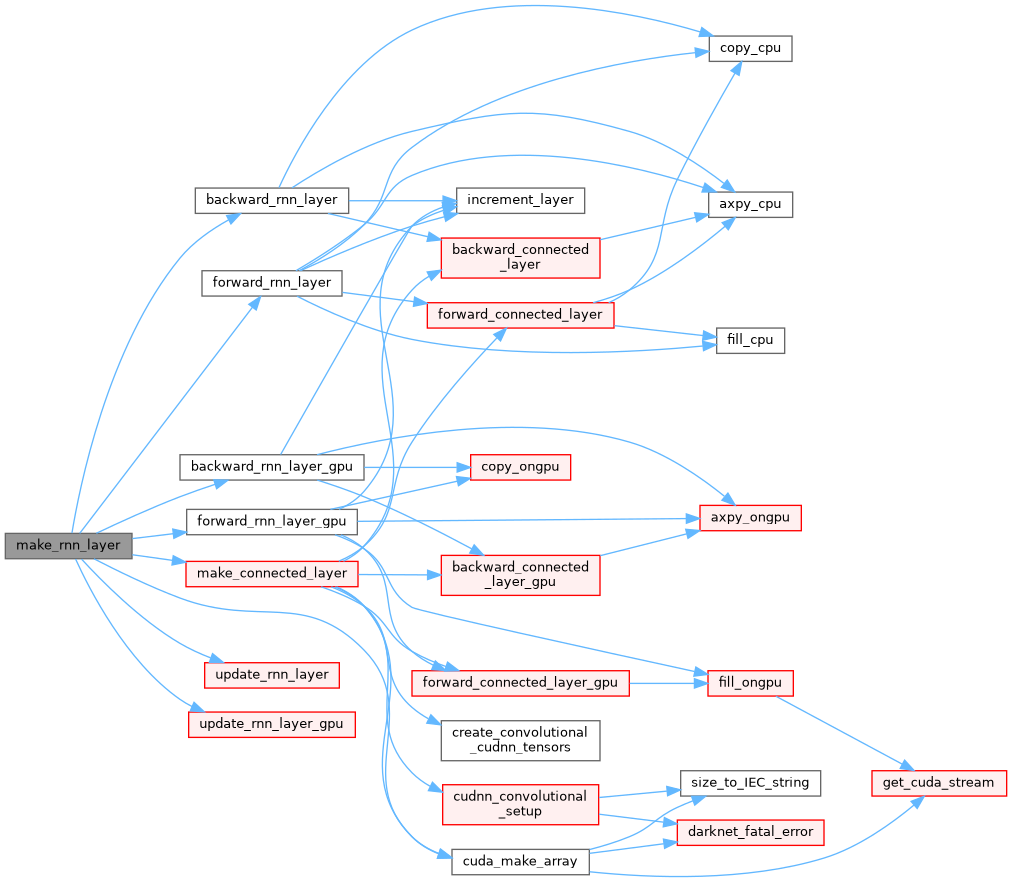
| Darknet::Layer | make_rnn_layer (int batch, int inputs, int hidden, int outputs, int steps, ACTIVATION activation, int batch_normalize, int log) |
| void | update_rnn_layer (Darknet::Layer &l, int batch, float learning_rate, float momentum, float decay) |
| #define USET |
| void backward_rnn_layer | ( | Darknet::Layer & | l, |
| Darknet::NetworkState | state | ||
| ) |

| void forward_rnn_layer | ( | Darknet::Layer & | l, |
| Darknet::NetworkState | state | ||
| ) |

| Darknet::Layer make_rnn_layer | ( | int | batch, |
| int | inputs, | ||
| int | hidden, | ||
| int | outputs, | ||
| int | steps, | ||
| ACTIVATION | activation, | ||
| int | batch_normalize, | ||
| int | log | ||
| ) |

| void update_rnn_layer | ( | Darknet::Layer & | l, |
| int | batch, | ||
| float | learning_rate, | ||
| float | momentum, | ||
| float | decay | ||
| ) |